Регулярные выражения используются для сжатого описания некоторого
множества строк с помощью шаблонов, без необходимости перечисления
всех элементов этого множества или явного написания функции для проверки.
Большинство символов соответствуют сами себе («a» соответствует «a» и т. д.).
Исключения из этого правила называются метасимволами: +-*/()^$.!?{}[]\|.
Термин «Регулярные выражения» является переводом с английского словосочетания "Regular expressions".
Перевод не очень точно отражает смысл, правильнее было бы «шаблонные выражения».
Регулярное выражение, или коротко «регулярка», состоит из обычных символов и специальных командных последовательностей.
Например, \d задаёт любую цифру, а \d+ — задает любую последовательность из одной или более цифр.
Работа с регулярками реализована во всех современных языках программирования.
Однако существует несколько «диалектов», поэтому функционал регулярных выражений может различаться от языка к языку.
В некоторых языках программирования регулярками пользоваться очень удобно (например, в питоне), в некоторых — не слишком (например, в C++).
Примеры регулярных выражений
Регулярка
Её смысл
simple text
В точности текст «simple text»
\d{5}
Последовательности из 5 цифр
\d означает любую цифру
{5} — ровно 5 раз
\d\d/\d\d/\d{4}
Даты в формате ДД/ММ/ГГГГ (и прочие куски, на них похожие, например, 98/76/5432)
\b\w{3}\b
«Слова» в точности из трёх букв/цифр
\b означает границу слова (с одной стороны буква/цифра, а с другой — нет)
\w — любая буква/цифра,
{3} — ровно три раза
[-+]?\d+
Целое число, например, 7, +17, -42, 0013 (возможны ведущие нули)
[-+]? — либо -, либо +, либо пусто
\d+ — последовательность из 1 или более цифр
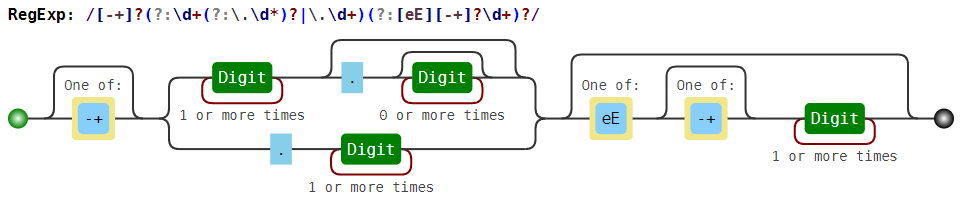
[-+]?(?:\d+(?:\.\d*)?|\.\d+)(?:[eE][-+]?\d+)?
Действительное число, возможно в экспоненциальной записи Например, 0.2, +5.45, -.4, 6e23, -3.17E-14. См. ниже картинку.
Сила и ответственность
Регулярные выражения, или коротко, регулярки — это очень мощный инструмент.
Но использовать их следует с умом и осторожностью, и только там, где они действительно приносят пользу, а не вред.
Во-первых, плохо написанные регулярные выражения работают медленно.
Во-вторых, их зачастую очень сложно читать, особенно если регулярка написана не лично тобой пять минут назад.
В-третьих, очень часто даже небольшое изменение задачи (того, что требуется найти) приводит к значительному изменению выражения.
Поэтому про регулярки часто говорят, что это write only code (код, который только пишут с нуля, но не читают и не правят).
А также шутят: Некоторые люди, когда сталкиваются с проблемой, думают «Я знаю, я решу её с помощью регулярных выражений.» Теперь у них две проблемы.
Вот пример write-only регулярки (для проверки валидности e-mail адреса (не надо так делать!!!)):
(?:[a-z0-9!#$%&'*+/=?^_`{|}~-]+(?:\.[a-z0-9!#$%&'*+/=?^_`{|}~-]+)*|"(?:[\x01-\x08\x0b\x0c\x0e-\x1f\x21\x23-\x5b\x5d-\x7f]| \\[\x01-\x09\x0b\x0c\x0e-\x7f])*")@(?:(?:[a-z0-9](?:[a-z0-9-]*[a-z0-9])?\.)+[a-z0-9](?:[a-z0-9-]*[a-z0-9])?|\[(?:(?:25[0-5]|
2[0-4][0-9]|[01]?[0-9][0-9]?)\.){3}(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?|[a-z0-9-]*[a-z0-9]: (?:[\x01-\x08\x0b\x0c\x0e-\x1f\x21-\x5a\x53-\x7f]|\\[\x01-\x09\x0b\x0c\x0e-\x7f])+)\])
А вот здесь более точная регулярка для проверки корректности email адреса стандарту RFC822. Если вдруг будете проверять email, то не делайте так! :)
Если адрес вводит пользователь, то пусть вводит почти что угодно, лишь бы там была собака.
Надёжнее всего отправить туда письмо и убедиться, что пользователь может его получить.
Могущественный текстовый редактор Sublime text 3, в котором очень удобный поиск по регуляркам;
Если вы используете Linux/Mac, то регулярки там можно использовать в командной строке с grep, в Vim/Emacs/...;
Основы синтаксиса
Любая строка (в которой нет символов .^$*+?{}[]\|()) сама по себе является регулярным выражением. Так, выражению Хаха будет соответствовать строка “Хаха” и только она.
Регулярные выражения являются регистрозависимыми, поэтому строка “хаха” (с маленькой буквы) уже не будет соответствовать выражению выше.
Подобно строкам в языке Python, регулярные выражения имеют спецсимволы .^$*+?{}[]\|(),
которые в регулярках являются управляющими конструкциями.
Для написания их просто как символов требуется их экранировать, для чего нужно поставить перед ними знак \.
Так же, как и в питоне, в регулярных выражения выражение \n соответствует концу строки, а \t — табуляции.
Шаблоны, соответствующие одному символу
Во всех примерах ниже соответствия регулярному выражению выделяются жёлтым цветом.
Шаблон
Описание
Пример
Применяем к тексту
.
Один любой символ, кроме новой строки \n.
м.л.ко
молоко, малако, Им0л0коИхлеб
\d
Любая цифра (d=digit character)
СУ\d\d
СУ35, СУ111, АЛСУ14
\D
Любой символ, кроме цифры
926\D123
9260123, 926)123, 1926-1234
\s
Любой пробельный символ (пробел, табуляция, конец строки и т.п.) (s=space character)
бор\sода
бор ода, бор ода, борода
\S
Любой непробельный символ
\S123
X123, я123, !123456, 1 + 123456
\w
Любая буква (то, что может быть символом слова любого естественного языка, кроме дефиса), а также цифры и _ (w=word character)
\w\w\w
Год, f_3, qwert
\W
Всё, что не подходит под \w
сом\W
сом!, сом?
[..]
Один из символов в скобках, любой символ из диапазона a-b или любой символ, соответствующий
\w, \d и т.д.
Буква “ё” не включается в общий диапазон букв! Вообще говоря, в \d включается всё, что в юникоде помечено как «цифра», а в \w — ещё и всё, помеченное буквой любого алфавита. Ещё много всего!
[abc-], [-1]
если нужен минус, его нужно указать последним или первым
[*[(+\\\]\t]
внутри скобок нужно экранировать только ] и \
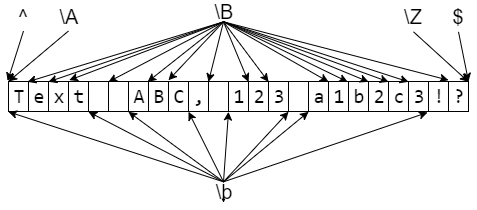
\b
Начало или конец слова (слева пусто или не-цифро-буква, справа цифро-буква и наоборот). В отличие от предыдущих соответствует позиции, а не символу (b=boundary)
\bвал
вал, валун, перевал, Перевалка
\bвал\b
вал, валун, перевал, Перевалка
\B
Не конец слова (либо внутри, либо вообще не в слове)
\Bвал
вал, валун, перевал, Перевалка
\Bвал\B
вал, валун, перевал, Перевалка
Разминка — 1
Интерактивная разминка
Напиши такие регулярные выражения, что каждая строка слева полностью подходят под шаблон,
а каждая строка справа не имеет соответствий шаблону.
0
Нужна хорошая регулярка!
Подходит
Не подходит
cat
#!&
123
?@(
a_2
[№]
0
Нужна хорошая регулярка!
Подходит
Не подходит
cat
123
dog
456
cow
789
0
Нужна хорошая регулярка!
Подходит
Не подходит
1+1
1-1
1+2
1-2
1+3
1-3
0
Нужна хорошая регулярка!
Подходит
Не подходит
a1A
aA1
B2b
Bb2
c3C
cC3
0
Нужна хорошая регулярка!
Подходит
Не подходит
abc
jkl
def
mlo
ghi
pqr
Квантификаторы (указание количества повторений)
Шаблон
Описание
Пример
Применяем к тексту
{n}
Ровно n повторений
\d{4}
1, 12, 123, 1234, 12345
{m,n}
От m до n повторений включительно
\d{2,4}
1, 12, 123, 1234, 12345
{m,}
Не менее m повторений
\d{3,}
1, 12, 123, 1234, 12345
{,n}
Не более n повторений
\d{,2}
1, 12, 123
?
Ноль или одно вхождение, синоним {0,1}
валы?
вал, валы, валов
*
Ноль или более, синоним {0,}
СУ\d*
СУ, СУ1, СУ12, ...
+
Одно или более, синоним {1,}
a\)+
a), a)), a))), ba)])
*?, +?, ?? {m,n}?, {,n}?, {m,}?
По умолчанию квантификаторы жадные (greedy) — захватывают максимально возможное число символов. Добавление ? делает их ленивыми (lazy), они захватывают минимально возможное число символов.
\(.*\)
\(.*?\)
(a + b) * (c + d) * (e + f) (a + b) * (c + d) * (e + f)
Жадность в регулярках и границы найденного шаблона
Как указано выше, по умолчанию квантификаторы жадные.
Скажем, шаблон \d+ захватывает максимально возможное количество цифр.
Поэтому можно быть уверенным, что перед найденным шаблоном не идёт цифра, и после не идёт цифра.
Однако если в шаблоне есть не жадные части (например, явный текст), то всё становится гораздо сложнее:
шаблону 1\d+9 в строке 0001555559000 соответствует 1555559.
Про жадность и лень будут подробности ниже.
Пересечение подстрок
В обычной ситуации регулярки позволяют найти только непересекающиеся шаблоны.
Вместе с проблемой границы слова это делает их использование в некоторых случаях более сложным.
Например, если мы решим искать e-mail адреса при помощи регулярки \w+@\w+, может найтись вот что:
foo@boo@goo@moo@roo@zoo
То есть это с одной стороны и не e-mail, а с другой стороны это не все подстроки вида текст-собака-текст,
так как boo@goo и moo@roo пропущены.
Разминка — 2
Интерактивная разминка
Напиши такие регулярные выражения, что каждая строка слева полностью подходят под шаблон,
а каждая строка справа не имеет соответствий шаблону.
0
Нужна хорошая регулярка!
Подходит
Не подходит
bkasldasiblask
no
qwelkjsalilk
yes
asdokakd
bug(
0
Нужна хорошая регулярка!
Подходит
Не подходит
asdfkljasdfFOO
asdfkljasdfGOO
asdf#123FOO
asdf#123GOO
asd !#\%@##$FOO
asd !#\%@##$GOO
0
Нужна хорошая регулярка!
Подходит
Не подходит
afoot
Atlas
catfoot
Aymoro
dogfoot
Iberic
fanfoot
Mahran
foody
Ormazd
foolery
Silipan
foolish
altared
fooster
chandoo
footage
crenel
foothot
crooked
footle
fardo
footpad
folksy
footway
forest
hotfoot
hebamic
jawfoot
idgah
mafoo
manlike
nonfood
marly
padfoot
palazzi
prefool
sixfold
sfoot
tarrock
unfool
unfold
0
Нужна хорошая регулярка!
Подходит
Не подходит
In some card games.
the Joker is a wildcard and can
represent any card in the deck.
With regular expressions,
you are often matching pieces of text.
that you don't know the exact contents of,
other than the fact that.
they share a common pattern or structure
0
Нужна хорошая регулярка!
Подходит
Не подходит
start a lot of stuff end
start stuff end
start b got of stuff end
no a lot of stuff to end
start c of bot stuff end
start very confused stuf
start stuff a lot of end
start too too too too too long line end
start of a stuff and end
stаrt a lоt оf stuff еnd
start lot a stuff of end
start a lоt оf stuff end
Регулярки в реальной жизни
В реальной жизни регулярки часто используются не для написания
программ, а для полуинтерактивнной обработки имеющегося текста.
И нормальная практика — написать что-нибудь простое, что
работает хотя бы в подавляющем большинстве случаев.
Если ложных срабатываний много — уточнить. Если немного — обработать их вручную.
Все задачи такого сорта не требуют совсем точной регулярки, необходимо и достаточно написать такую, которая проходит все открытые тесты.
Другой пример задач — это задачи валидации.
Например, валидация номера машины, номера телефона, номера паспорта, валидация числа, email'а и т.п.
Такие задачи требуют строгой проверки, они должны пропускать все правильные, и не пропускать ни одну неправильную.
В таких задачах будут тесты на все возможные отклонения.
A: Простые шаблоны
В этой задаче не нужно писать программу, а пока просто написать несколько регулярных выражений, по одному на строку.
Нужно написать регулярные выражения, которые позволят в тексте ниже найти:
все «натуральные числа» — последовательности только из цифр (возможно, окружённые буквами), например «ПРИ123ВЕТ»;
все последовательности из заглавной русской буквы и затем 1 и более любых русских букв. Например, «что заМирУНас_здесь, А?»;
все последовательности из как минимум двух звёздочек. Например, «123**12»;
все последовательности символов +-*/()^$.!?{}[]\|, например, «1\]]]]]^^3»;
все последовательности символов, отличных от символа конца строки и {;
куски вида {???}, где ??? не содержит в себе фигурных скобок, например «{{{ho-ho}}}».
Ответ на эту задачу должен выглядеть как-то так:
123*
[АБВ]где*
.*.*
[+символы]
\n|\{
{.*}
Интерактивная отладка — 1
0
Нужна хорошая регулярка!
Подходит
Не подходит
12345
hello
123
cat
0
Нужна хорошая регулярка!
Подходит
Не подходит
ПРИВЕТ
привет
Читай
читай
ДОКУМЕНТАЦИЮ
А
Не
гадай
ЁмоЁ
!
0
Нужна хорошая регулярка!
Подходит
Не подходит
**
*
***
!*!
****
!*!*!
0
Нужна хорошая регулярка!
Подходит
Не подходит
+-*/()^$.!?{}[]\|
Среди этих
++++()()()()[]
символов внутри
^$
квадратных скобок
^|||$
экранируй только
\/\/
слеш, минус, закрывающую квадратную
Интерактивная отладка — 2
0
Нужна хорошая регулярка!
Регулярные выражения представляют собой похожий, но гораздо более
сильный инструмент для поиска строк, проверки их на соответствие
какому-либо шаблону и другой подобной работы. Англоязычное название
этого инструмента — Regular Expressions или просто RegExp.
* Найдите все последовательности цифр (абв1313где);
* Найдите все последовательности русских букв,
написанные заглавными (аааБББввв);
* Найдите последовательности цифро-букв (\w), начинающихся с
русской буквы и содержащих внутри цифру (torБОР_18годYEAR!, 18, ё18);
* Найдите все слова (последовательности русских и английских букв, дефисов),
начинающиеся с большой русской или латинской буквы (Привет, зайдиЗа-Мной8);
* Найдите все натуральные числа, не находящиеся внутри или на границе слова
(\b — граница слова);
* Найдите строчки, в которых есть символ *;
* Найдите строчки, в которых есть открывающая и когда-нибудь потом
закрывающая скобки;
* Выделите одним махом весь кусок оглавления (в конце примера);
АААА аааа АаАаАаАа {123 123 12345} 11223344
А1Б2В3 АА11 ББ22ВВ 33ГГ44
Тест! { Ещё! { Даёшь! } ЁЁЁёёё }
QwertyЙцукен
+-,/[](), *** (***), a*(b+[c+d])*e/f+g-h
!!"""####%%%%%&&&'''(((())***++++,,,,,-----..//:::;;;;<<<<<===>>>????
@@@@@[[[[\\\ ]]]]]^^^__`````{{{{|||||}}}}}~~~~~
{h3}CamelCase -> under_score{/h3};
{h3}Удаление повторов{/h3};
{h3}Форматирование номера телефона{/h3};
{h3}Поиск e-mail'ов — 2{/h3};
The Greedy Trap, The Lazy Trap, The Ugly Trap
Сравним поведение жадного и ленивого квантивикатора:
Жадный
Соответствия жадному
Ленивый
Соответствия ленивому
Начало\d+
Начало123412341234Конец
Начало\d+?
Начало123412341234Конец
В примере выше \d+ захватывает все цифры, до которых может дотянуться.
\d+? — наоборот, берёт возможный минимум, то есть ровно одну цифру.
Начало\d+2
Начало123412341234Конец
Начало\d+?2
Начало123412341234Конец
Однако эта жадность и ленность — «покорная» (docile): если нужно «пожертвовать» некоторым числом цифр ради соответствия шаблону, то это будет сделано. Ещё бывают супержадные (possessive) квантификаторы, такие цифр не отдают.
Жадные квантификаторы из примера выше работают так: сначала захватывается все возможные цифры.
Потом делается попытка «пристроить» оставшуюся часть шаблона. Если это не получается, цифры по одной «возвращаются» назад (backtracking), и снова производится попытка пристроить оставшуюся часть шаблона.
Ленивые квантификаторы из примера выше работают так: сначала захватывается всего одна цифра.
Потом делается попытка «пристроить» оставшуюся часть шаблона. Если это не получается, цифры по одной «добавляются», и снова производится попытка пристроить оставшуюся часть шаблона.
<h3>.*</h3>
До <h3>Первый</h3> <h3>Второй</h3> После
<h3>.*?</h3>
До <h3>Первый</h3> <h3>Второй</h3> После
Эта штука называется Greedy Trap — жадная ловушка. Мы пытаемся выделить небольшой блок от текста до текста, но по пути захватываем целые блоки до самого последнего. Неприятная штука. Лечение — использование ленивых квантификаторов.
<h3>.*</h3>!
До <h3>Первый</h3>? <h3>Второй</h3>! После
<h3>.*?</h3>!
До <h3>Первый</h3>? <h3>Второй</h3>! После
Эта штука называется Lazy Trap — ленивая ловушка. Мы пытаемся выделить небольшой блок, после которого идёт восклицательный знак. Но оказывается, что гораздо раньше есть скрока, подходящая под начало шаблона, и мы по пути захватываем целые блоки до самого последнего. Неприятная штука. Лечение — достаточно трудоёмкое. Нужно сделать так, чтобы часть .*? не могла содержать других концов блока. В простейшем случае можно использовать что-то в духе [^>]*?, но это не всегда работает идеально.
Регулярки в питоне
Функции для работы с регулярками живут в модуле re.
Основные функции:
Функция
Её смысл
re.search(pattern, string)
Найти в строке string первую строчку, подходящую под шаблон pattern;
re.fullmatch(pattern, string)
Проверить, подходит ли строка string под шаблон pattern;
re.split(pattern, string, maxsplit=0)
Аналог str.split(), только разделение происходит по подстрокам, подходящим под шаблон pattern;
re.findall(pattern, string)
Найти в строке string все непересекающиеся строки, подходящие под шаблон pattern;
re.finditer(pattern, string)
Итератор всем непересекающимся строкам, подходящим под шаблон pattern в строке string (выдаются match-объекты);
re.sub(pattern, repl, string, count=0)
Заменить в строке string все непересекающиеся соответствия шаблону pattern на repl;
Пример использования всех основных функций
import re
match = re.search(r'\d\d\D\d\d', r'Телефон 123-12-12')
print(match.group(0) if match else 'Not found')
# -> 23-12
match = re.search(r'\d\d\D\d\d', r'Телефон 1231212')
print(match.group(0) if match else 'Not found')
# -> Not found
match = re.fullmatch(r'\d\d\D\d\d', r'12-12')
print('YES' if match else 'NO')
# -> YES
match = re.fullmatch(r'\d\d\D\d\d', r'Т. 12-12')
print('YES' if match else 'NO')
# -> NO
print(re.split(r'\W+', 'Где, скажите мне, мои очки??!'))
# -> ['Где', 'скажите', 'мне', 'мои', 'очки', '']
print(re.findall(r'\d\d\.\d\d\.\d{4}',
r'Эта строка написана 19.01.2018, а могла бы и 01.09.2017'))
# -> ['19.01.2018', '01.09.2017']
for m in re.finditer(r'\d\d\.\d\d\.\d{4}', r'Эта строка написана 19.01.2018, а могла бы и 01.09.2017'):
print('Дата', m.group(0), 'начинается с позиции', m.start())
# -> Дата 19.01.2018 начинается с позиции 20
# -> Дата 01.09.2017 начинается с позиции 45
print(re.sub(r'\d\d\.\d\d\.\d{4}',
r'DD.MM.YYYY',
r'Эта строка написана 19.01.2018, а могла бы и 01.09.2017'))
# -> Эта строка написана DD.MM.YYYY, а могла бы и DD.MM.YYYY
Тонкости экранирования в питоне ('\\\\\\\\foo')
Так как символ \ в питоновских строках также необходимо экранировать, то в результате в шаблонах могут возникать конструкции вида '\\\\par'.
Первый слеш означает, что следующий за ним символ нужно оставить «как есть». Третий также.
В результате с точки зрения питона '\\\\' означает просто два слеша \\.
Теперь с точки зрения движка регулярных выражений, первый слеш экранирует второй.
Тем самым как шаблон для регулярки '\\\\par' означает просто текст \par.
Для того, чтобы не было таких нагромождений слешей, перед открывающей кавычкой нужно поставить символ r, что скажет питону «не рассматривай \ как экранирующий символ (кроме случаев экранирования открывающей кавычки)».
Соответственно можно будет писать r'\\par'.
Использование дополнительных флагов в питоне
Каждой из функций, перечисленных выше, можно дать дополнительный параметр flags, что несколько изменит режим работы регулярок.
В качестве значения нужно передать сумму выбранных констант, вот они:
Константа
Её смысл
re.ASCII
По умолчанию \w, \W, \b, \B, \d, \D, \s, \S соответствуют все юникодные символы с соответствующим качеством. Например, \d соответствуют не только арабские цифры, но и вот такие: ٠١٢٣٤٥٦٧٨٩. re.ASCII ускоряет работу, если все соответствия лежат внутри ASCII.
re.IGNORECASE
Не различать заглавные и маленькие буквы. Работает медленнее, но иногда удобно
re.MULTILINE
Специальные символы ^ и $ соответствуют началу и концу каждой строки
re.DOTALL
По умолчанию символ \n конца строки не подходит под точку. С этим флагом точка — вообще любой символ
Для написания и тестирования регулярных выражений удобно использовать сервис https://regex101.com (не забудьте поставить галочку Python в разделе FLAVOR слева) или текстовый редактор Sublime text 3.
Замечание по вводу-выводу
Прочитать весь текст разом из стандартного ввода можно при помощи строчек
import sys
text = sys.stdin.read()
При тестировании для того, чтобы завершить ввод, который считывается целиком, нужно нажать Ctrl+D.
Также текст условия можно считывать из файла input.txt, который при тестировании должен располагаться в той же папке, что и исходный код.
text = open('input.txt', encoding='utf-8').read()
В тестах не будет излишнего занудства.
То есть сокращения \d, \w можно использовать достаточно вольно, если не написано обратного.
Специально злые сценарии будут только в задачах на валидацию.
B: Валидация регистрационного знака легкового автомобиля
В России применяются регистрационные знаки нескольких видов.
Общего в них то, что они состоят из цифр и букв.
Причём используются только 12 букв кириллицы, имеющие графические аналоги в латинском алфавите — А, В, Е, К, М, Н, О, Р, С, Т, У и Х.
У частных легковых автомобилях номера — это буква, три цифры, две буквы, затем две или три цифры с кодом региона.
Есть также и другие виды, но в этой задаче они не понадобятся.
Вам потребуется определить, является ли последовательность букв корректным номером легкового автомобиля.
На вход даётся число N, затем N строк с номером.
Если строка является корректным номером частного легкового автомобиля, то выведите Private, иначе — Fail.
Буквы в номере могут быть большими и маленькими, как русскими, так и латинскими.
Слово — это последовательность из букв (русских или английских), внутри которой могут быть дефисы.
На вход даётся текст, посчитайте, сколько в нём слов.
PS. Задача решается в одну строчку. Никакие хитрые техники, не упомянутые выше, не требуются.
Он --- серо-буро-малиновая редиска!!
>>>:->
А не кот.
www.kot.ru
9
Интерактивная отладка
0
Нужна хорошая регулярка!
Он --- серо-буро-малиновая редиска!!
>>>:->
А не кот.
www.kot.ru
-Он --- -серо-буро-малиновая -редиска!!
>>>:->
-А -не -кот.
-www.-kot.-ru
Он- --- серо-буро-малиновая- редиска-!!
>>>:->
А- не- кот-.
www-.kot-.ru-
О-н --- серо-буро-мали-новая ред-иска!!
>>>:->
А не к-от.
www.k-ot.ru
Слово — это последовательность из букв (русских или английских), внутри которой могут быть дефисы.
На вход даётся текст, посчитайте, сколько в нём слов.
PS. Задача решается в одну строчку. Никакие хитрые техники, не упомянутые выше, не требуются.
E: Поиск e-mail'ов
Допустимый формат e-mail адреса регулируется стандартом RFC 5322. Если говорить вкратце,
то e-mail состоит из одного символа @ (at-символ или собака), текста до собаки (Local-part)
и текста после собаки (Domain part). Вообще в адресе может быть всякий беспредел (вкратце можно
прочитать о нём в википедии). Довольно странные штуки могут быть валидным адресом, например:
"very.(),:;<|>[]\".VERY.\"very@\\ \"very\".unusual"@[IPv6:2001:db8::1]
"()<|>[]:,;@\\\"!#$%&'-/=?^_`{}| ~.a"@(comment)exa-mple
Но большинство почтовых сервисов такой ад и вакханалию не допускают. И мы тоже не будем :)
Кстати, полезно знать, что часть адреса между символом + и @ игнорируется, поэтому можно использовать
синонимы своего адреса (например, shаshkоv+spam@179.ru и shаshkоv+vk@179.ru), для того, чтобы
упростить себе сортировку почты. (Правда не все сайты позволяют использовать "+", увы)
D: Поиск e-mail'ов
Допустимый формат e-mail адреса регулируется стандартом RFC 5322.
Если говорить вкратце, то e-mail состоит из одного символа @ (at-символ или собака), текста до собаки (Local-part) и текста после собаки (Domain part).
Вообще в адресе может быть всякий беспредел (вкратце можно прочитать о нём в википедии).
Довольно странные штуки могут быть валидным адресом, например:
"very.(),:;<>[]\".VERY.\"very@\\ \"very\".unusual"@[IPv6:2001:db8::1] "()<>[]:,;@\\\"!#$%&'-/=?^_`{}| ~.a"@(comment)exa-mple Но большинство почтовых сервисов такой ад и вакханалию не допускают.
И мы тоже не будем :)
Кстати, полезно знать, что часть адреса между символом + и @ игнорируется, поэтому можно использовать синонимы своего адреса (например, shаshkоv+spam@179.ru и shаshkоv+vk@179.ru), для того, чтобы упростить себе сортировку почты.
(Правда не все сайты позволяют использовать "+", увы)
Будем рассматривать только адреса, имя которых (Local-part, часть до @) состоит из не более, чем 64 латинских букв, цифр и символов «'._+-», а домен (Domain part, часть после @) — из не более, чем 255 латинских букв, цифр и символов «.-».
При этом адрес не может ни начинаться, ни заканчиваться на символы «'.+-»).
На вход даётся текст. Необходимо вывести все e-mail адреса, которые в нём встречаются в соответствие с описанием выше.
Считаем, что e-mail может быть частью «слова», то есть в boo@ya_ru мы видим адрес boo@ya, а в foo№boo@ya.ru видим boo@ya.ru.
PS. Совсем не обязательно делать все проверки только регулярками. Регулярные выражения — это просто инструмент, который делает часть задач простыми. Не нужно делать их назад сложными :)
Иван Иванович! Нужен ответ на письмо от ivanoff@ivan-chai.ru.
Не забудьте поставить в копию serge'o-lupin@mail.ru- это важно.
ivanoff@ivan-chai.ru
serge'o-lupin@mail.ru
WRONG BUT OK: foo.@ya.ru, foo@.ya.ru
PARTLY: boo@ya_ru, .boo@ya.ru., foo#boo@ya.ru
foo.@ya.ru
foo@.ya.ru
boo@ya
boo@ya.ru
boo@ya.ru
Интерактивная отладка
0
Нужна хорошая регулярка!
Иван Иванович! Нужен ответ на письмо от ivanoff@ivan-chai.ru.
Не забудьте поставить в копию serge'o-lupin@mail.ru- это важно.
NO: foo.@ya.ru, foo@.ya.ru
PARTLY: boo@ya_ru, .boo@ya.ru., foo#boo@ya.ru
'a@b.ru 'a@b.ru' a@b.ru' a.@b.ru' a@.b.ru' a..a@b.ru' a!@b.ru' a@!b.ru' a@@b.ru'
.a@b.ru .a@b.ru. a@b.ru. a.@b.ru. a@.b.ru. a..a@b.ru. a!@b.ru. a@!b.ru. a@@b.ru.
_a@b.ru _a@b.ru_ a@b.ru_ a.@b.ru_ a@.b.ru_ a..a@b.ru_ a!@b.ru_ a@!b.ru_ a@@b.ru_
+a@b.ru +a@b.ru+ a@b.ru+ a.@b.ru+ a@.b.ru+ a..a@b.ru+ a!@b.ru+ a@!b.ru+ a@@b.ru+
-a@b.ru -a@b.ru- a@b.ru- a.@b.ru- a@.b.ru- a..a@b.ru- a!@b.ru- a@!b.ru- a@@b.ru-
abcdefgtuvwxyz'._+-ABCDEFGHXYZ0123489@abcdefghixyz.-ABCDEFGHIZ0123456789.ru
abcdefgtuvwxyz'._+-ABCDEFGHWXYZ0123789@abcdefghwxyz.-ABCDEFGHYZ0123489.ru
abcdefgtuvwxyz'._+-ABCDEFGHWXYZ0123789@abcdefghwxyz.-ABCDEFGHYZ0123489.ru
abcdefgtuvwxyz'._+-ABCDEFGHXYZ#0123789@abcdefghwxyz.-ABCDEFGHYZ0123489.ru
abcdefgtuvwxyz'._+-ABCDEFGHXYZ0123489@abcdefghiwxyz.-ABCDEFGHYZ0123489.ru
abcdefgtuvwxyz'._+-ABCDEFGHXYZ0123489@abcdefghixyz.-ABCDEFG..XYZ0123789.ru
abcdefgtuvwxyz'._+-ABCDEFGHXYZ0123489@abcdefghixyz.-ABCDEFGHIXYZ0123789.ru
abcdefgtuvwxyz'._+-ABCDEFGHXYZ0{12378}9@abcdefgvwxyz.-ABCDEFGXYZ0123789.ru
abcdefgtuvwxyz'._+-ABCDEFGHXYZ0123489@abcdefghixyz.-ABCDEFGHIZ0123459.ru
Скобочные группы (?:...) и перечисления |
Перечисления (операция «ИЛИ»)
Чтобы проверить, удовлетворяет ли строка хотя бы одному из шаблонов, можно воспользоваться аналогом оператора or, который записывается с помощью символа |.
Так, некоторая строка подходит к регулярному выражению A|B тогда и только тогда, когда она подходит хотя бы к одному из регулярных выражений A или B.
Например, отдельные овощи в тексте можно искать при помощи шаблона морковк|св[её]кл|картошк|редиск.
Скобочные группы (группировка плюс квантификаторы)
Зачастую шаблон состоит из нескольких повторяющихся групп. Так, MAC-адрес сетевого устройства обычно записывается как шесть групп из двух шестнадцатиричных цифр, разделённых символами - или :.
Например, 01:23:45:67:89:ab.
Каждый отдельный символ можно задать как [0-9a-fA-F], и можно весь шаблон записать так:
Ситуация становится гораздо сложнее, когда количество групп заранее не зафиксировано.
Чтобы разрешить эту проблему в синтаксисе регулярных выражений есть группировка (?:...).
Можно писать круглые скобки и без значков ?:, однако от этого у группировки значительно меняется смысл, регулярка начинает работать гораздо медленнее.
Об этом будет написано ниже.
Итак, если REGEXP — шаблон, то (?:REGEXP) — эквивалентный ему шаблон.
Разница только в том, что теперь к (?:REGEXP) можно применять квантификаторы, указывая, сколько именно раз должна повториться группа.
Например, шаблон для поиска MAC-адреса, можно записать так:
[0-9a-fA-F]{2}(?:[:-][0-9a-fA-F]{2}){5}
Скобки плюс перечисления
Также скобки (?:...) позволяют локализовать часть шаблона, внутри которой происходит перечисление.
Например, шаблон
(?:он|тот) (?:шёл|плыл) соответствует каждой из строк «он шёл», «он плыл», «тот шёл», «тот плыл», и является синонимом
он шёл|он плыл|тот шёл|тот плыл.
Ещё примеры
Шаблон
Применяем к тексту
(?:[а-я][а-я]\d\d)+
Есть миг29а, ту154б. Некоторые делают даже миг29ту154ил86.
(?:[а-я]+\d+)+
Есть миг29а, ту154б. Некоторые делают даже миг29ту154ил86.
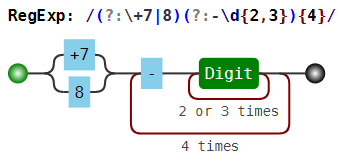
(?:\+7|8)(?:-\d{2,3}){4}
+7-926-123-12-12, 8-926-123-12-12
(?:[Хх][аоеи]+)+
Муха — хахахехо, ну хааахооохе, да хахахехохииии! Хам трамвайный.
\b(?:[Хх][аоеи]+)+\b
Муха — хахахехо, ну хааахооохе, да хахахехохииии! Хам трамвайный.
E: Замена времени
Вовочка подготовил одно очень важное письмо, но везде указал неправильное время.
Поэтому нужно заменить все вхождения времени на строку (TBD).
Время — это строка вида HH:MM:SS или HH:MM, в которой HH — число от 00 до 23, а MM и SS — число от 00 до 59. Важное письмо — это «приличный» русский текст, в нём нет безобразий в духе «00:0a:12:30:0b:cd» или «ААА12:30OGM!»
Уважаемые! Если вы к 09:00 не вернёте чемодан,
то уже в 09:00:01 я за себя не отвечаю.
PS. С отношением 25:50 всё нормально!
Уважаемые! Если вы к (TBD) не вернёте чемодан,
то уже в (TBD) я за себя не отвечаю.
PS. С отношением 25:50 всё нормально!
Интерактивная отладка
0
Нужна хорошая регулярка!
Уважаемые! Если вы к 09:00 не вернёте чемодан,
то уже в 09:00:01 я за себя не отвечаю.
PS. С отношением 25:50 всё нормально!
a 00:42:13 b 00:42:00 c 00:42: d 00:42 e
a 00:49:13 b 00:49:00 c 00:49: d 00:49 e
a 00:56:13 b 00:56:00 c 00:56: d 00:56 e
a 00:63:13 b 00:63:00 c 00:63: d 00:63 e
a 00:70:13 b 00:70:00 c 00:70: d 00:70 e
a 03:00:13 b 03:00:00 c 03:00: d 03:00 e
a 21:56:13 b 21:56:00 c 21:56: d 21:56 e
a 21:63:13 b 21:63:00 c 21:63: d 21:63 e
a 21:70:13 b 21:70:00 c 21:70: d 21:70 e
a 04:63:13 b 14:63:00 c 24:63: d 24:63 e
a 04:70:13 b 14:70:00 c 24:70: d 24:70 e
a 07:00:13 b 17:00:00 c 27:00: d 27:00 e
a 07:07:13 b 17:07:00 c 27:07: d 27:07 e
F: Действительные числа в паскале
В языке паскаль действительное число должно либо содержать десятичную точку, либо экспоненту (которая начинается с буквы e или E), либо и то и другое. Если число содержит десятичную точку, то с обеих сторон от неё должна быть хотя бы одна цифра.
И перед числом, и перед экспонентой могут стоять знаки + и -.
Перед и после числа может стоять любое число пробелов, но их не может быть внутри числа.
При этом нет никаких ограничений на размер получившегося числа.
На вход даются строки. Ввод заканчивается звёздочкой.
Для каждой строки выведите результат проверки в соответствии с примером ниже.
1.2 is legal.
1. is illegal.
1.0e-55 is legal.
e-12 is illegal.
6.5E is illegal.
1e-12 is legal.
+4.1234567890E-99999 is legal.
7.6e+12.5 is illegal.
99 is illegal.
Интерактивная отладка
0
Нужна хорошая регулярка!
Подходит
Не подходит
1.2
1.0e-55
1.
1e-12
e-12
+4.1234567890E-99999
6.5E
1.2
7.6e+12.5
1.0e-55
99
1e-12
123 456
+4.1234567890E-99999
2.2.2.
1.2
.2
1.2e+45
.
+0.00
2.e1
13.123
1e+2.2
+13.123
-e3
-13.123
e-12
13.123e56
6.5E
+13.123e56
7.6e+12.5
-13.123e56
12.34e45E45
13.123e+56
100
+13.123e+56
100.4e34.8
-13.123e+56
1.2e+4 5
13.123e-56
++56.90
+13.123e-56
*45
-13.123e-56
-13.123e+-56
G: Аббревиатуры
Владимир устроился на работу в одно очень важное место. И в первом же документе он ничего не понял,
там были сплошные ФГУП НИЦ ГИДГЕО, ФГОУ ЧШУ АПК и т.п.
Тогда он решил собрать все аббревиатуры, чтобы потом найти их расшифровки на http://sokr.ru/.
Помогите ему.
Будем считать аббревиатурой слова только лишь из русских заглавных букв (как минимум из двух).
Если несколько таких слов разделены одним пробелом, то они вместе считаются одной аббревиатурой.
Это курс информатики соответствует ФГОС и ПООП,
это подтверждено ФГУ ФНЦ НИИСИ РАН
ФГОС
ПООП
ФГУ ФНЦ НИИСИ РАН
Интерактивная отладка
0
Нужна хорошая регулярка!
Это курс информатики соответствует ФГОС и ПООП,
это подтверждено ФГУ ФНЦ НИИСИ РАН
ФБР [фэ-бэ-э́р] — Федеральное бюро расследований
ЛФК [эл-фэ-ка́] — лечебная физическая культура
РФФ [эр-фэ-фэ́] — радиофизический факультет
ЧИК ЧК ЧМ ЧМТ
ЧОН
ЧОП
ЧП ЧП ЧР ЧРИ ЧС ЧСВ ЧССР-ЧСФР-ЧФ
ЧЭЗ
Ш
ШИЗО
H: С-строка
Строки в языке C (в Питоне действуют аналогичные правила) заключаются в двойные кавычки, при этом сам символ кавычек в строке должен быть экранирован символом обратного слэша “\”.
Аналогично обратный слэш, обозначающий в строке символ “\”, тоже должен быть экранирован: “\\”. Также разрешены конструкции вида “\n”, обозначающие специальные символы, но не “\ ” — экранирование "ничего": пробельных символов.
Определите по данной строке, является ли она корректной С-строкой.
В проверяющую систему необходимо сдать лишь само регулярное выражение.
Корректная строка должна полностью удовлетворять шаблону, некорректная — не содержать частей, удовлетворяющих шаблону.
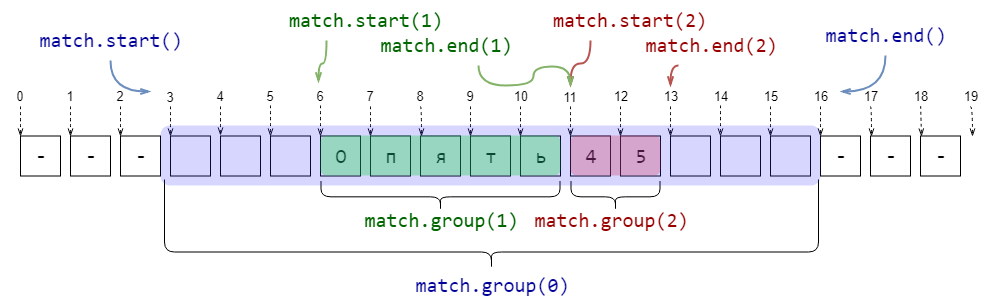
Группирующие скобки (...) и match-объекты в питоне
Match-объекты
Если функции re.search, re.fullmatch не находят соответствие шаблону в строке, то они возвращают None, функция re.finditer возващает пустой итератор.
Однако если соответствие найдено, то возвращается match-объект.
Эта штука содержит в себе кучу полезной информации о соответствии шаблону.
В отличие от предыдущих функций, re.findall возвращает «простой и понятный» список соответствий.
Полный набор атрибутов match-объекта можно посмотреть в документации, а здесь приведём самое полезное.
Метод
Описание
Пример
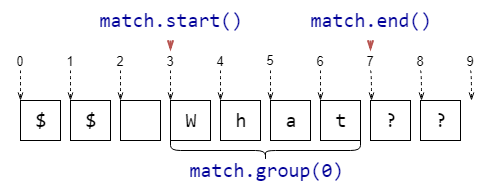
match.group()
Подстрока, соответствующая всему шаблону
match = re.search(r'\w+', r'$$ What??') match.group() # -> 'What'
match.start()
Индекс в исходной строке, начиная с которого идёт найденная подстрока
match = re.search(r'\w+', r'$$ What??') match.start() # -> 3
match.end()
Индекс в исходной строке, который следует сразу за найденной подстрока
match = re.search(r'\w+', r'$$ What??') match.end() # -> 7
Группирующие скобки (...)
Если в шаблоне регулярного выражения встречаются скобки (...) без ?:, то они становятся группирующими.
В match-объекте, который возвращают re.search, re.fullmatch и re.finditer, по каждой такой группе можно получить ту же информацию, что и по всему шаблону. А именно часть подстроки, которая соответствует (...), а также индексы начала и окончания в исходной строке. Достаточно часто это бывает полезно.
import re
pattern = r'\s*([А-Яа-яЁё]+)(\d+)\s*'
string = r'--- Опять45 ---'
match = re.search(pattern, string)
print(f'Найдена подстрока >{match.group(0)}< с позиции {match.start(0)} до {match.end(0)}')
print(f'Группа букв >{match.group(1)}< с позиции {match.start(1)} до {match.end(1)}')
print(f'Группа цифр >{match.group(2)}< с позиции {match.start(2)} до {match.end(2)}')
###
# Найдена подстрока > Опять45 < с позиции 3 до 16
# Группа букв >Опять< с позиции 6 до 11
# Группа цифр >45< с позиции 11 до 13
Тонкости со скобками и нумерацией групп.
Если к группирующим скобкам применён квантификатор (то есть указано число повторений), то подгруппа в match-объекте будет создана только для последнего соответствия.
Например, если бы в примере выше квантификаторы были снаружи от скобок '\s*([А-Яа-яЁё])+(\d)+\s*', то вывод был бы таким:
Найдена подстрока > Опять45 < с позиции 3 до 16
Группа букв >ь< с позиции 10 до 11
Группа цифр >5< с позиции 12 до 13
Внутри группирующих скобок могут быть и другие группирующие скобки.
В этом случае их нумерация производится в соответствии с номером появления открывающей скобки с шаблоне.
import re
pattern = r'((\d)(\d))((\d)(\d))'
string = r'123456789'
match = re.search(pattern, string)
print(f'Найдена подстрока >{match.group(0)}< с позиции {match.start(0)} до {match.end(0)}')
for i in range(1, match.groups()+1):
print(f'Группа №{i} >{match.group(i)}< с позиции {match.start(i)} до {match.end(i)}')
###
Найдена подстрока >1234< с позиции 0 до 4
Группа №1 >12< с позиции 0 до 2
Группа №2 >1< с позиции 0 до 1
Группа №3 >2< с позиции 1 до 2
Группа №4 >34< с позиции 2 до 4
Группа №5 >3< с позиции 2 до 3
Группа №6 >4< с позиции 3 до 4
Группы и re.findall
Если в шаблоне есть группирующие скобки, то вместо списка найденных подстрок будет возвращён список кортежей, в каждом из которых только соответствие каждой группе. Это не всегда происходит по плану, поэтому обычно нужно использовать негруппирующие скобки (?:...).
Если в шаблоне нет группирующих скобок, то re.split работает очень похожим образом на str.split.
А вот если группирующие скобки в шаблоне есть, то между каждыми разрезанными строками будут все соответствия каждой из подгрупп.
В некоторых ситуация эта возможность бывает чрезвычайно удобна!
Например, достаточно из предыдущего примера убрать лишние группы, и польза сразу станет очевидна!
Напиши такие регулярные выражения, чтобы в результате получились получились указанные группы.
0
Нужна хорошая регулярка!
Строка для поиска
Группа 1
Группа 2
Группа 3
Группа 4
2018.10.13
2018
10
13
2019/11/24
2019
11
24
В дату 1024-02-29 пришли они
1024
02
29
Просты числа 1024, 53, 17 не походят
Большие тоже: 12345-123-12
0
Нужна хорошая регулярка!
Строка для поиска
Группа 1
Группа 2
Группа 3
{h3}text{/h3} {h3}text2{/h3}
text
{h3 class="foo"}other{/h3}
class="foo"
other
В этой не самой простой задаче полезно помнить следующее достаточно логичное свойство перечислений в группах (?:foo|boo|zoo): варианты перебираются в порядке слева направо.
Обычно это не имеет значения, но если некоторый вариант является префиксом другого, например, (?:fooboo|foo) то порядок имеет ещё какое значение.
Если написать (?:foo|fooboo), то вариант fooboo никогда не реализуется.
В таких случая перечислять нужно строго от самых длинных к самым коротким.
0
Нужна хорошая регулярка!
Строка для поиска
Группа 1
Группа 2
"строка" и "другая"
строка
до "строки" и "после"
строки
так, "кавычка ' внутри" и "снаружи"
кавычка ' внутри
тут "кавычку \" экранировать \"!", "а \" б"
кавычку \" экранировать \"!
emptyemptyemptyemptyemptyemptyemptyemptyempty
до "тонкости\\" "экранирования"
тонкости\\
до "тонкости\\\" этого" "экранирования"
тонкости\\\" этого
до "жесть\\ \" угар \\\" \\\\" "тут нет"
жесть\\ \" угар \\\" \\\\
Использование групп при заменах
Использование групп добавляет замене (re.sub, работает не только в питоне, а почти везде) очень удобную возможность: в шаблоне для замены можно ссылаться на соответствующую группу при помощи \1, \2, \3, ....
Например, если нужно даты из неудобного формата ММ/ДД/ГГГГ перевести в удобный ДД.ММ.ГГГГ, то можно использовать такую регулярку:
import re
text = "We arrive on 03/25/2018. So you are welcome after 04/01/2018."
print(re.sub(r'(\d\d)/(\d\d)/(\d{4})', r'\2.\1.\3', text))
# -> We arrive on 25.03.2018. So you are welcome after 01.04.2018.
Если групп больше 9, то можно ссылаться на них при помощи конструкции вида \g<12>.
Замена с обработкой шаблона функцией в питоне
Ещё одна питоновская фича для регулярных выражений: в функции re.sub вместо текста для замены можно передать функцию, которая будет получать на вход match-объект и должна возвращать строку, на которую и будет произведена замена.
Это позволяет не писать ад в шаблоне для замены, а использовать удобную функцию.
Например, «зацензурим» все слова, начинающиеся на букву «Х»:
import re
def repl(m):
return '>censored(' + str(len(m.group(0))) + ')<'
text = "Некоторые хорошие слова подозрительны: хор, хоровод, хороводоводовед."
print(re.sub(r'\b[хХxX]\w*', repl, text))
# -> Некоторые >censored(7)< слова подозрительны: >censored(3)<, >censored(7)<, >censored(15)<.
Ссылки на группы при поиске
При помощи \1, \2, \3, ... и \g<12> можно ссылаться на найденную группу и при поиске (backrefs).
Необходимость в этом встречается не так часто, но это бывает полезно при обработке простых xml и html.
Только пообещайте, что не будете парсить сложный xml и тем более html при помощи регулярок!
Регулярные выражения для этого не подходят. Используйте другие инструменты.
Каждый раз, когда неопытный программист парсит html регулярками, в мире умирает котёнок.
Если кажется «Да здесь очень простой html, напишу регулярку», то сразу вспоминайте шутку про две проблемы.
Не нужно пытаться парсить html регулярками, даже Пётр Митричев не сможет это сделать в общем случае :)
Использование регулярных выражений при парсинге html подобно залатыванию резиновой лодки шилом.
Закон Мёрфи для парсинга html и xml при помощи регулярок гласит: парсинг html и xml регулярками иногда работает, но в точности до того момента, когда правильность результата будет очень важна.
import re
text = "SPAM <foo>Here we can <boo>find</boo> something interesting</foo> SPAM"
print(re.search(r'<(\w+?)>.*?</\1>', text)[0])
# -> <foo>Here we can <boo>find</boo> something interesting</foo>
text = "SPAM <foo>Here we can <foo>find</foo> OH, NO MATCH HERE!</foo> SPAM"
print(re.search(r'<(\w+?)>.*?</\1>', text)[0])
# -> <foo>Here we can <foo>find</foo>
Разминка — 4
Интерактивная разминка
Обратные ссылки (backrefs) — классная штука.
Правда обычно они работают не совсем так как в мануалах: обычно не очень понятно, как именно их нужно воткнуть :)
0
Нужна хорошая регулярка!
Подходит
Не подходит
кускус
убоина
тамтам
бархан
варвар
земляк
канкан
сорить
тартар
чурбак
пурпур
ворюга
водовод
локоть
берберы
маркер
колокол
канцер
барбарис
черешок
староста
масштаб
полполка
саквояж
естество
отметина
берберка
прозреть
берберин
утренник
шахиншах
сборщица
варварка
горизонт
алькальд
кожевник
Сделаем вид, что это — не то же самое, что и предыдущая разминка.
Это ведь даже немного правда, не так ли?
0
Нужна хорошая регулярка!
Подходит
Не подходит
анна
иней
касса
жулан
мокко
хонда
ванна
слюна
гамма
зелье
хиппи
крона
лотто
турка
миссис
армада
пассаж
тангаж
атташе
сканье
осанна
атлант
вассал
увечье
трасса
скупка
баллада
барахло
шиллинг
эффенди
комиссия
апельсин
стаккато
этнограф
пассажир
веснушки
I: Шифровка
Владимиру потребовалось срочно запутать финансовую документацию. Но так, чтобы это было обратимо.
Он не придумал ничего лучше, чем заменить каждое целое число (последовательность цифр) на его куб. Помогите ему.
Было закуплено 12 единиц техники по 410.37 рублей.
Было закуплено 1728 единиц техники по 68921000.50653 рублей.
J: То ли акростих, то ли акроним, то ли апроним
Акростих — осмысленный текст, сложенный из начальных букв каждой строки стихотворения.
Акроним — вид аббревиатуры, образованной начальными звуками (напр. НАТО, вуз, НАСА, ТАСС), которое можно произнести слитно (в отличие от аббревиатуры, которую произносят «по буквам», например: КГБ — «ка-гэ-бэ»).
На вход даётся текст. Выведите слитно первые буквы каждого слова.
Буквы необходимо выводить заглавными.
Эту задачу можно решить в одну строчку.
Московский государственный институт международных отношений
МГИМО
микоян авиацию снабдил алкоголем,
народ доволен работой авиаконструктора
МАСАНДРА
Интерактивная отладка
0
Нужна хорошая регулярка!
микоян авиацию снабдил алкоголем,
народ доволен работой авиаконструктора
K: Хайку
Хайку — жанр традиционной японской лирической поэзии века, известный с XIV века.
Оригинальное японское хайку состоит из 17 слогов, составляющих один столбец иероглифов.
Особыми разделительными словами — кирэдзи — текст хайку делится на части из 5, 7 и снова 5 слогов.
При переводе хайку на западные языки традиционно вместо разделительного слова использую разрыв строки и, таким образом, хайку записываются как трёхстишия.
Перед вами трёхстишия, которые претендуют на то, чтобы быть хайку.
В качестве разделителя строк используются символы / .
Если разделители делят текст на строки, в которых 5/7/5 слогов, то выведите «Хайку!».
Если число строк не равно 3, то выведите строку «Не хайку. Должно быть 3 строки.»
Иначе выведите строку вида «Не хайку. В i строке слогов не s, а j.», где строка i — самая ранняя, в которой количество слогов неправильное.
Для простоты будем считать, что слогов ровно столько же, сколько гласных, не задумываясь о тонкостях.
Вечер за окном. / Еще один день прожит. / Жизнь скоротечна...
Хайку!
Просто текст
Не хайку. Должно быть 3 строки.
Как вишня расцвела! / Она с коня согнала / И князя-гордеца.
Не хайку. В 1 строке слогов не 5, а 6.
На голой ветке / Ворон сидит одиноко... / Осенний вечер!
Не хайку. В 2 строке слогов не 7, а 8.
Тихо, тихо ползи, / Улитка, по склону Фудзи, / Вверх, до самых высот!
Не хайку. В 1 строке слогов не 5, а 6.
Жизнь скоротечна... / Думает ли об этом / Маленький мальчик.
Хайку!
Интерактивная отладка
0
Нужна хорошая регулярка!
Просто текст
Как вишня расцвела! / Она с коня согнала / И князя-гордеца.
На голой ветке / Ворон сидит одиноко... / Осенний вечер!
Тихо, тихо ползи, / Улитка, по склону Фудзи, / Вверх, до самых высот!
Жизнь скоротечна... / Думает ли об этом / Маленький мальчик.
L: Смайлик
Составьте регулярное выражение, соответствующее смайлику.
Смайлик состоит из трёх частей: глаз, носа (который может отсутствовать) и рта. Глаза это один символ “:” или “;”. Нос это один символ “-”. Рот состоит из одного или более одинаковых символов рта: “)”, “(”, “/”, “\”, “|”, “D”.
В проверяющую систему необходимо сдать лишь само регулярное выражение.
Смайлик должен полностью удовлетворять шаблону, не-смайлик — не содержать частей, удовлетворяющих шаблону.
:)
;-///
)))
:-()
YES
YES
NO
NO
Интерактивная отладка
0
Нужна хорошая регулярка!
Подходит
Не подходит
:)
:;-)(\/|D
;-///
)))
:)
:-()
:-)
::))
;)
;--|
;-(
;()
:(((
:-|||||/
;-DDD
:\-/
:-||||
:-
:/
:
:-\
;--
;\\\
-)
:-////
))
M: Проверка на простоту
Натуральное число N будем записывать при помощи N единиц подряд.
Составьте регулярное выражение проверяющее, что данное число является составным.
Выражение должно работать для всех натуральных чисел, больших 1.
Например, регулярное выражение ^(11){2,}$ правильно работает для всех чисел от 2 до 8, но дает неверный ответ для числа 9.
В проверяющую систему необходимо сдать лишь само регулярное выражение.
Составное число должно полностью удовлетворять шаблону, простое — не содержать частей, удовлетворяющих шаблону.
11
1111
NO
YES
Интерактивная отладка
0
Нужна хорошая регулярка!
Подходит
Не подходит
1111
11
111111
111
11111111
11111
111111111
1111111
1111111111
11111111111
111111111111
1111111111111
N: Разность в унарной записи
Натуральное число N будем записывать при помощи N единиц подряд.
Составьте регулярное выражение проверяющее, что тождество вида x - y = z для чисел в унарной записи верно.
В проверяющую систему необходимо сдать лишь само регулярное выражение.
Верное тождество должно полностью удовлетворять шаблону, неверное — не содержать частей, удовлетворяющих шаблону.
11111 - 11 = 111
11111 - 11 = 11
YES
NO
Интерактивная отладка
0
Нужна хорошая регулярка!
Подходит
Не подходит
111 - 11 = 1
1 - 1111 = 111
1111 - 1 = 111
1111111 - 11 = 11
11111 - 1 = 1111
1111111 - 1111111 = 1111111
11111 - 11 = 111
111111111 - 111 = 111
11111 - 1111 = 1
111111111 - 111 = 1111111
111111 - 1 = 11111
1111111111 - 11 = 111111
111111 - 11 = 1111
1111111111 - 11 = 1111111
111111 - 1111 = 11
1111111111 - 111 = 11
1111111 - 11111 = 11
1111111111 - 111 = 111111111
11111111 - 111111 = 11
1111111111 - 1111 = 111
11111111 - 1111111 = 1
1111111111 - 1111 = 1111
111111111 - 111 = 111111
1111111111 - 11111 = 1111111
111111111 - 111111 = 111
1111111111 - 111111 = 1111111111
111111111 - 1111111 = 11
1111111111 - 1111111 = 11111
111111111 - 1111111 = 11
1111111111 - 1111111 = 1111111
Шаблоны, соответствующие не конкретному тексту, а позиции
Отдельные части регулярного выражения могут соответствовать не части текста, а позиции в этом тексте.
То есть такому шаблону соответствует не подстрока, а некоторая позиция в тексте, как бы «между» буквами.
Простые шаблоны, соответствующие позиции
Для определённости строку, в которой мы ищем шаблон, будем называть всем текстом.
Каждую строчку всего текста (то есть каждый максимальный кусок без символов конца строки) будем называть строчкой текста.
Шаблон
Описание
Пример
Подходящие строки
^
Начало всего текста или начало строчки текста, если flag=re.MULTILINE
^Привет
$
Конец всего текста или конец строчки текста, если flag=re.MULTILINE
Будь здоров!$
\A
Строго начало всего текста
\Z
Строго конец всего текста
\b
Начало или конец слова (слева пусто или не-цифро-буква, а справа цифро-буквы, либо наоборот)
\bвал
вал, перевал
\B
Не граница слова (либо и слева, и справа цифро-буквы, либо и слева, и справа НЕ цифро-буквы)
\Bвал
перевал, вал
Разминка — 5
Интерактивная разминка
Все эти ключи чрезвычайно полезны.
Именно поэтому они уже встречались в примерах и заданиях выше.
В этом задании главное — не заснуть!
0
Нужна хорошая регулярка!
Подходит
Не подходит
сонм
ясон
сонет
аксон
сонар
фасон
сонник
таксон
соната
унисон
сонетка
кильсон
сонливец
шансонье
сонорика
персонаж
Сложные шаблоны, соответствующие позиции (lookaround и Co)
Следующие шаблоны применяются в основном в тех случаях, когда нужно уточнить, что должно идти непосредственно перед или после шаблона, но при этом не включать найденное в match-объект.
В принципе, это можно сделать и при помощи группирующих скобок, однако наиболее существенная польза lookaround'ов в том, что по ним шаблоны могут пересекаться!
Шаблон
Описание
Пример
Применяем к тексту
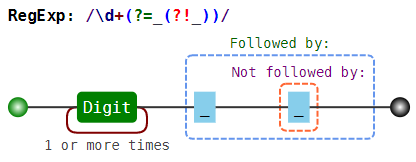
(?=...)
lookahead assertion, соответствует каждой позиции, сразу после которой начинается соответствие шаблону "..."
Isaac (?=Asimov)
Isaac Asimov, Isaac other
(?!...)
negative lookahead assertion, соответствует каждой позиции, сразу после которой НЕ может начинаться шаблон "..."
Isaac (?!Asimov)
Isaac Asimov, Isaac other
(?<=...)
positive lookbehind assertion, соответствует каждой позиции, на которой может заканчиваться шаблон "..." Длина шаблона должна быть фиксированной, то есть abc и a|b — это ОК, а a* и a{2,3} — нет.
(?<=abc)def
abcdef, bcdef
(?<!...)
negative lookbehind assertion, соответствует каждой позиции, на которой НЕ может заканчиваться шаблон "..."
(?<!abc)def
abcdef, bcdef
На всякий случай ещё раз. Каждый их этих шаблонов проверяет лишь то, что идёт непосредственно перед позицией или непосредственно после позиции. Если пару таких шаблонов написать рядом, то проверки будут независимы (то есть будут соответствовать AND в каком-то смысле).
lookaround на примере королей и императоров Франции
Последовательность цифр, после которой идёт ровно одно подчёркивание
12_34__56
^(?:(?!boo).)*?$
Строка, в которой нет boo (то есть нет такого символа, перед которым есть boo)
a foo and
boo and zoo
and others
^(?:(?!boo)(?!foo).)*?$
Строка, в которой нет ни boo, ни foo
a foo and
boo and zoo
and others
Прочие фичи
Конечно, здесь описано не всё, что умеют регулярные выражения, и даже не всё, что умеют регулярные выражения в питоне.
За дальнейшим можно обращаться к этому разделу.
Из полезного за кадром осталась компиляция регулярок для ускорения многократного использования одного шаблона, использование именных групп и разные хитрые трюки.
O: CamelCase -> under_score
Владимир написал свой открытый проект, именуя переменные в стиле «ВерблюжийРегистр».
И только после того, как написал о нём статью, он узнал, что в питоне для имён переменных принято использовать подчёркивания для разделения слов (under_score). Нужно срочно всё исправить, пока его не «закидали тапками».
Задача могла бы оказаться достаточно сложной, но, к счастью, Владимир совсем не использовал строковых констант.
Поэтому любая последовательность букв и цифр, внутри которой есть и строчные, и заглавные, — это имя переменной, которое нужно поправить.
Довольно распространённая ошибка ошибка — это повтор слова.
Вот в предыдущем предложении такая допущена.
Необходимо исправить каждый такой повтор (слово, один или несколько пробельных символов, и снова то же слово).
Довольно распространённая ошибка
ошибка — это лишний повтор повтор слова слова.
Смешно, не не правда ли?
Не нужно портить хор хоровод.
Довольно распространённая ошибка — это лишний повтор слова.
Смешно, не правда ли?
Не нужно портить хор хоровод.
Интерактивная отладка
0
Нужна хорошая регулярка!
Довольно распространённая ошибка
ошибка — это лишний повтор повтор слова слова.
Смешно, не не правда ли?
Не нужно портить хор хоровод.
Q: Близкие слова
Для простоты будем считать словом любую последовательность букв, цифр и знаков _ (то есть символов \w).
Дан текст. Необходимо найти в нём любой фрагмент, где сначала идёт слово «олень», затем не более 5 слов, и после этого идёт слово «заяц».
Да он олень, а не заяц!
олень, а не заяц
Интерактивная отладка
0
Нужна хорошая регулярка!
Вот олень, заяц!
Да он олень, не заяц!
Да он олень, а не заяц!
Да он олень, а не этот заяц!
Да он олень, а не этот самый заяц!
Да он олень, а не этот самый белый заяц!
Да он олень, а не этот самый белый подбитый заяц!
Да он олень, а не этот самый белый подбитый одноглазый заяц!
R: Форматирование больших чисел
Большие целые числа удобно читать, когда цифры в них разделены на тройки запятыми.
Переформатируйте целые числа в тексте.
Здесь оказывается удивительно полезным тот факт, что lookahead части у разных совпадений шаблону могут совпадать.
Запятую нужно поставить во всякое место, после которого идёт число цифр, кратное 3.
12 мало
лучше 123
1234 почти
12354 хорошо
стало 123456
супер 1234567
12 мало
лучше 123
1,234 почти
12,354 хорошо
стало 123,456
супер 1,234,567
Интерактивная отладка
0
Нужна хорошая регулярка!
12 мало
лучше 123
1234 почти
12354 хорошо
стало 123456
супер 1234567
S: Разделить текст на предложения
Для простоты будем считать, что:
каждое предложение начинается с заглавной русской или латинской буквы;
каждое предложение заканчивается одним или несколькими знаками препинания .;!?;
между словами и предложениями может быть любой непустой набор пробельных символов;
внутри предложений нет заглавных и точек (нет пакостей в духе «Мы любим творчество А. С. Пушкина)».
Разделите текст на предложения так, чтобы каждое предложение занимало одну строку.
Пустых строк в выводе быть не должно.
Любые наборы из более одного пробельного символа замените на один пробел.
В этом
предложении разрывы строки... Но это
не так важно! Совсем? Да, совсем! И это
не должно мешать.
В этом предложении разрывы строки...
Но это не так важно!
Совсем?
Да, совсем!
И это не должно мешать.
Интерактивная отладка
0
Нужна хорошая регулярка!
В этом
предложении разрывы строки... Но это
не так важно! Совсем? Да, совсем! И это
не должно мешать.
T: Форматирование номера телефона
Если вы когда-нибудь пытались собирать номера мобильных телефонов, то наверняка знаете, что почти любые 10 человек используют как минимум пяток различных способов записать номер телефона.
Кто-то начинает с +7, кто-то просто с 7 или 8, а некоторые вообще не пишут префикс.
Трёхзначный код кто-то отделяет пробелами, кто-то при помощи дефиса, кто-то скобками (и после скобки ещё пробел некоторые добавляют).
После следующих трёх цифр кто-то ставит пробел, кто-то дефис, кто-то ничего не ставит. И после следующих двух цифр — тоже.
А некоторые начинают за здравие, а заканчивают... В общем очень неудобно!
На вход даётся номер телефона, как его мог бы ввести человек.
Необходимо его переформатировать в формат +7 123 456-78-90.
Если с номером что-то не так, то нужно вывести строчку Fail!.
+7 123 456-78-90
+7 123 456-78-90
8(123)456-78-90
+7 123 456-78-90
7(123) 456-78-90
+7 123 456-78-90
1234567890
+7 123 456-78-90
123456789
Fail!
+9 123 456-78-90
Fail!
+7 123 456+78=90
Fail!
+7(123 45678-90
+7 123 456-78-90
8(123 456-78-90
Fail!
Интерактивная отладка
0
Нужна хорошая регулярка!
Строка для поиска
Группа 1
Группа 2
Группа 3
Группа 4
+7 123 456-78-90
123
456
78
90
8(123)456-78-90
123
456
78
90
7(123) 456-78-90
123
456
78
90
1234567890
123
456
78
90
+7(123 45678-90
123
456
78
90
123456789
+9 123 456-78-90
+7 123 456+78=90
8(123 456-78-90
U: Сравнение URL
Для идентификации ресурсов в сети Internet используются URL
(Uniform Resource Locator). URL состоит из нескольких элементов:
протокол, хост, порт, путь, файл и секция. Некоторые элементы
URL могут быть опущены. Рассмотрим упрощенный формат URL:
[протокол://]хост[:порт][путь/[файл[#секция]]]
Заключенные в квадратные скобки элементы могут быть опущены,
т.е. например, можно не указать протокол или секцию. Но, например, если указан файл,
то обязательно должен быть указан путь. Регистр букв в элементах URL не важен.
Рассмотрим кратко все элементы URL:
Протокол — это способ доступа к файлу, URL
с разными протоколами и одинаковыми остальными элементами могут указывать на различные ресурсы.
Хост и порт — это имя некоторого сервера в сети
и способ доступа к нему (порт — натуральное число, не превосходящее 65535).
Путь представляет собой путь к файлу, содержащему запрашиваемый ресурс,
от некоторого каталога на сервере, который называется корневым.
При этом для разделения имен каталогов используется символ "/".
Путь, если он не пуст, всегда начинается с символа "/".
Специальное обозначение "." соответствует самому каталогу, ".." — родительскому каталогу.
Файл — это файл, содержащий запрашиваемый ресурс.
Наконец, файл может быть разбит на секции каким либо способом и можно указать,
к какой именно секции вы хотите обратиться.
Различные символы в URL могут быть заменены своими шестнадцатеричными ASCII
кодами с помощью символа "%", например a = %41, Z = %5A.
В коде всегда используется ровно две шестнадцатеричные цифры.
Некоторые символы могут встречаться в элементах URL только как шестнадцатеричные коды —
все символы, кроме букв латинского алфавита, цифр и символов "." и "-",
а некоторые не могут встречаться вообще: "\", "#","*", "@", "%", "?", ":",
",", а также символы с ASCII-кодом меньше %20. Символ "/" может встречаться в элементах
URL только в пути для разделения входящих в него каталогов. Имя файла не может состоять только из точек.
Ваша цель в этой задаче — помочь разработчикам web-сервера.
Для web-сервера отсутствующие части URL имеют следующие значения по умолчанию:
Протокол: http
Порт: 80
Путь: пустая строка
Файл: index.html
Секция: пустая строка
Различные как строки URL могут указывать на один и тот же ресурс, например следующие три URL:
neerc.ifmo.ru http://neerc.ifmo.ru:80/index.html# Http://NEERC.IFMO.Ru/Dir/../././
Для разграничения доступа к ресурсам необходимо уметь определять,
указывают ли два различных URL на один и тот же ресурс. Помогите разработчикам написать соответствующую проверку.
Входные данные состоят из двух строк, каждая из них содержит URL.
Оба URL удовлетворяют формату, приведенному в условии этой задачи.
Длина каждого URL не превосходит 200 символов. Гарантируется, что ни один
из промежуточных каталогов на пути к ресурсу не лежит выше корневого каталога
(т.е. не может встретиться, например, URL http://somewhere.com/../dir/index.html)
а также, что имена всех каталогов состоят по крайней мере из одного символа
(два символа "/" не могут идти подряд в любом месте, кроме
как непосредственно после двоеточия после имени протокола).
Выведите YES, если оба URL, приведенные во входных данных, указывают на один и тот же ресурс, и NO в противном случае.
Вычисление остатка от деления при помощи регулярных выражений — совершенно необходимое умение для служителя культа регулярных выражений.
Это задание интересно тем, что здесь пригодятся супержадные (posessive) квантификаторы.
Эти взятого не отдают.
Вот пример: строка «xxx» полностью соответсвтует шаблону «x*.».
Последний символ «x» «достаётся» точке.
А вот супержадному шаблону «x*+.» здесь нет соответствий: «x*+» захватит все три «x» и ни одного не отдаст, поэтому на точку ничего не останется.
0
Нужна хорошая регулярка!
Подходит
Не подходит
1 % 1111 = 1
1 % 111 = 11111111
11 % 1111111 = 11
11 % 1111111 = 111111111
11 % 111111111111111 = 11
111 % 11 = 11
111 % 111111 = 111
1111 % 111 = 11
1111 % 111 = 1
1111 % 11111 = 1
1111 % 111111 = 1111
1111 % 11111111 = 1
11111 % 11 = 1
11111 % 111 = 1111
1111111 % 111 = 1
11111 % 11111 = 11111
11111111 % 111 = 11
1111111 % 11 = 111111111
111111111 % 111111 = 111
11111111 % 111 = 1
111111111 % 1111111 = 11
11111111 % 111111 = 1111
1111111111 % 111 = 1
111111111111 % 11 = 1
11111111111 % 111 = 11
111111111111 % 111 = 1
111111111111 % 11111 = 11
111111111111 % 1111 = 111
111111111111 % 11111111 = 1111
1111111111111 % 111111 = 11
1111111111111 % 11 = 1
1111111111111 % 1111111 = 1
1111111111111 % 111111 = 1
11111111111111 % 111 = 11111
11111111111111 % 11111 = 1111
11111111111111 % 11111 = 111
111111111111111 % 111111 = 111
111111111111111 % 111111 = 11
111111111111111 % 1111111 = 1
111111111111111111 % 1111 = 1
Проверка на простоту — 2
В прошлый раз нужно было найти составное число.
Это — было просто. Да-да, не-простое — просто.
А здесь нужно найти именно простое!
lookaround в помощь!
0
Нужна хорошая регулярка!
Подходит
Не подходит
11
1111
111
111111
11111
11111111
1111111
111111111
11111111111
1111111111
1111111111111
111111111111
Не степень двойки
Мы делали это уже два раза. Сделаем ещё два.
0
Нужна хорошая регулярка!
Подходит
Не подходит
111
1
11111
11
111111
1111
1111111
11111111
111111111
1111111111111111
1111111111
11111111111111111111111111111111
11111111111
11111111111111111111111111111111
111111111111
1111111111111111
1111111111111
11111111
11111111111111
1111
111111111111111
11
11111111111111111
1
Степень двойки
Здесь тоже нужно осмотреться. Ну, если вы понимаете, о чём я.