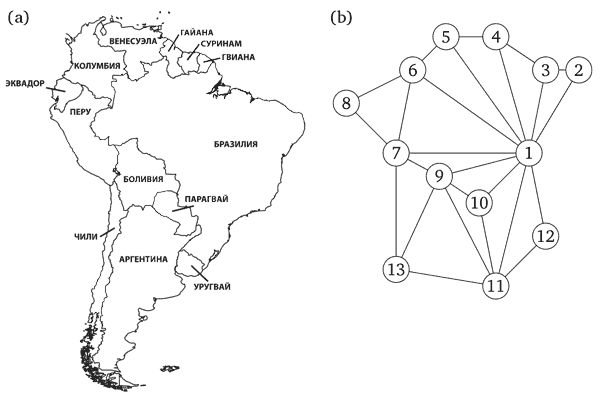
Многие важные задачи легко формулируются на языке графов.
Пусть, например, мы хотим выбрать цвет для каждой страны на карте,
при этом соседи должны иметь разные цвета (иначе не будет видна их общая граница).
Какое минимальное число цветов для этого нужно?
Видно, что карта (см. рис. ниже) содержит много лишнего: моря, реки и т.п.
Достаточно построить граф, изобразив каждую страну вершиной (в нашем примере 1 – Бразилия, 11 – Аргентина и т.д.) и соединив соседей ребром.
Надо покрасить все вершины графа в минимальное число цветов, при этом концы каждого ребра должны быть разного цвета.
Одна и та же математическая формулировка возникает в разных практических задачах. Пусть, например, мы хотим назначить даты экзаменов так,
чтобы никому не надо было сдавать два экзамена в один день, и при этом
хотим занять поменьше дней. Заведём вершину для каждого экзамена и соединим две вершины ребром, если хотя бы один студент сдаёт оба экзамена.
Раскрасив граф в минимальное число цветов, получим оптимальное расписание (экзамены одного цвета назначаются на один день).
Граф задаётся множеством вершин V и множеством рёбер E, соединяющих пары вершин.
(Английская терминология: вершина называется vertex или node, а ребро — edge.)
В примере с картой V = {1, 2, 3, ..., 13}, а рёбра из E соединяют страны,
граничащие друг с другом (в частности, E содержит рёбра {1, 2}, {9, 11} и
{7, 13}). Отношение «быть соседом» симметрично, так что ребро из x в y возникает одновременно с ребром из y в x.
Поэтому мы записываем ребро, соединяющее x с y, как множество: {x, y}.
Такие рёбра называются неориентированными (undirected), а соответствующий граф — неориентированным графом (undirected graph).
Бывают и несимметричные отношения, и их изображают ориентированными рёбрами (directed edges).
В ориентированном графе наличие ребра из x в y не гарантирует наличие ребра из y в x.
Ориентированное ребро из x в y будем обозначать (x, y).
Можно считать «всемирную паутину» (World Wide Web) ориентированным графом: из вершины u идёт ориентированное ребро в вершину v,
если на странице u есть ссылка на страницу v.
В этом графе миллиарды вершин и рёбер, так что алгоритмы, с ним работающие, должны
быть быстрыми (к счастью, такие алгоритмы есть — многое можно сделать
за линейное время).
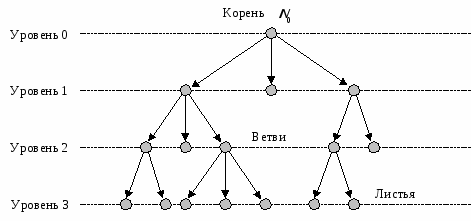
Корневые деревья
Начнём знакомство с графами с самыми простыми с точки зрения их структуры графами --- корневыми деревьями.
Напомним, деревом называется связный граф без циклов.
Дерево с отмеченной вершиной — корнем — называется корневым деревом.
В отличие от обычных деревьев, корневые обычно рисуют корнем к верху.
Итак, отмеченную вершину называют корнем.
Как известно, в дереве между любыми двумя вершинами существует ровно один путь.
Возьмём любую вершину и соединим её путём с корнем.
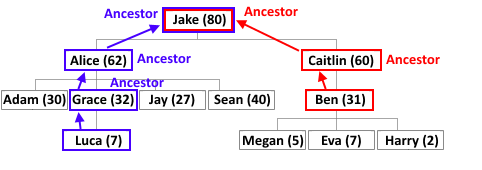
Все вершины в этом пути, кроме исходной, называются её предками (ancestor).
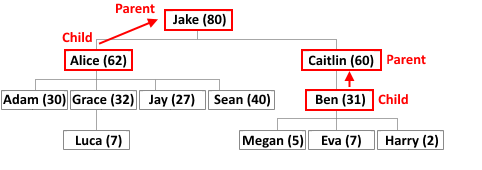
Вершина, следующая в этом пути за исходной, называются её родителем (parent).
Корень — это единственная вершина в дереве, у которой нет ни родителей, ни предков вообще.
На этой картинке Grace, Alice и Jake являются предками Luca, Caitlin и Jake — предками Ben.
Jake является общим предком Luca и Ben (а заодно и общим предком вообще всех вершин).
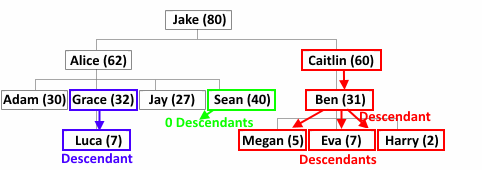
Если вершина А является предком вершины Б, то Б называется потомком (descendant) А.
Для данной вершины А множеством её потомков являются все вершины, не совпадающие с А, путь из которых к корню проходит через А.
Аналогично, если вершина А — родитель вершины Б, то вершина Б называется сыновьей (child) для А.
Здесь уже всё понятно, у каждой вершины, кроме корня, есть единственный родитель.
Luca — единственный потомок Grace.
У Caitlin четыре потомка — Ben, Megan, Eva и Harry.
И наконец у Sean нет потомков.
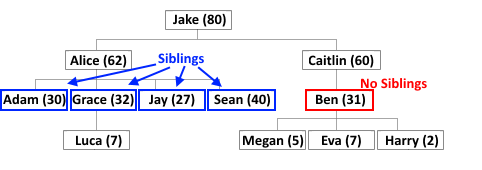
Вершины, у которых общий родитель, называются братьями (sibling).
И наконец вершины, у которых нет потомков, называются листьями.
Как хранить деревья в программе
В языке Python для этой задачи есть очень удобные для этого структуры — словари и множества.
Будем хранить два словаря — parents и children.
В каждом словаре в качестве ключей будут участвовать все вершины дерева и только они.
Пусть A — некоторая вершина.
Тогда parents[A] — это предок этой вершины, либо None для корня.
А children[A] — это множество всех потомков этой вершины.
Также корень дерева будем хранить в переменной root.
Например, дерево с картинок выше будем хранить так:
Такой способ хранения, вообще говоря, избыточен.
По словарю children можно восстановить словарь parents и наоборот.
И по любому из этих словарей можно найти корень.
Однако он достаточно удобен.
Напоминание про множества и словари
Про множества
Задание множеств
A = set() # Пустое множество
A = {1, 2, 'hello'} # Явное перечисление элементов
A = set('hello') # Множество букв в строке
B = [1, 2, 1, 2]; A = set(B) # Множество из списка или любого итерируемого объекта
A = {i**2 for i in range(10)} # Генератор множеств
Работа с элементами множеств
C = {1, 2, 'hello'}
for elem in C: # Перебираем все элементы множества
print(elem)
sorted(C) # Список из отсортированных элементов множества
1 in C # Проверка принадлежности
A.add(3) # Добавление элемента
A.remove(3) # Удаление элемента, который есть в множестве
A.discard(4) # Удаление элемента, которого может не быть в множестве
A.pop() # Извлечение случайного элемента из множества с удалением его
Операции с множествами
len(A) # Количество элементов в множестве
A | B # Возвращает множество, являющееся объединением множеств A и B.
A |= B # Добавляет в множество A все элементы из множества B.
A & B # Возвращает множество, являющееся пересечением множеств A и B.
A &= B # Оставляет в множестве A только те элементы, которые есть в множестве B.
A - B # Возвращает разность множеств A и B (A, но не B).
A -= B # Удаляет из множества A все элементы, входящие в B.
A ^ B # Возвращает симметрическую разность множеств A и B.
A ^= B # Записывает в A симметрическую разность множеств A и B.
A <= B # Возвращает true, если A является подмножеством B.
A >= B # Возвращает true, если B является подмножеством A.
A < B # Эквивалентно A <= B and A != B
A > B # Эквивалентно A >= B and A != B
Про словари
Задание словарей
D = {} # Пустой словарь
D = {1: 'a', 2: 'b'} # Явное перечисление
D = dict([(1, 'a'), (2, 'b')]) # Словарь из списка пар элементов
D = dict(zip([1, 2], ['a', 'b'])) # Словарь из итерируемого объекта, возвращающего пары элементов (ключ-значение)
D = {i: chr(i + ord('a')) for i in range(1, 3)} # Генератор словарей
Работа с элементами словаря
len(D) # Количество элементов в словаре
D[key] # Поиск по ключу, который есть в словаре
key in D # Проверка принадлежности словарю
D[key] = value # Установка или изменение значения
del D[key] # Удаление ключа, который есть в словаре
value = D.pop(key) # Удаления ключа вместе с возвращением значения
value = D.pop(key, no_key_value) # Удаления ключа вместе с возвращением значения. Если ключа нет, то no_key_value
key, value = D.popitem() # Извлечение из словаря пары (ключ, значение) с удалением ключа
D.get(key, no_key_value) # Значение по ключу, no_key_value, если ключа нет
D[key] = D.get(key, 0) + 1 # Самая простая реализация счётчика
for key in D: # Перебираем все ключи
print(key, D[key])
for key, value in D.items(): # Перебираем все пары (ключ, значение)
print(key, value)
for value in D.values(): # Перебор всех значений
print(value)
sorted(D) # Отсортированный список ключей
sorted(D.values()) # Отсортированный список значений
sorted(D.items()) # Отсортированный по ключу список пар (ключ, значение)
sorted(D.items(), key=lambda x: x[1]) # Отсортированный по значению список пар (ключ, значение)
A: Заполнение словаря родителей
Программа получает на вход число элементов в дереве N.
Далее следует N-1 строка, задающие родителя для каждого элемента дерева, кроме корня.
Каждая строка имеет вид имя_потомка имя_родителя.
Программа должна сформировать словарь parents и вывести его при помощи функции pprint из модуля pprint.
12
Alice Jake
Caitlin Jake
Adam Alice
Grace Alice
Jay Alice
Sean Alice
Ben Caitlin
Eva Ben
Harry Ben
Megan Ben
Luca Grace
Да, мне кажется, что я уже достаточно думал над этой задачей
Чес-слово! :)
Для того, чтобы не пропустить корень, нужно добавлять в словарь parents не только потомка, но и родителя со ссылкой на None,
если он ещё не встречался раньше.
IDE
B: Заполнение словаря потомков
Программа получает на вход число элементов в дереве N.
Далее следует N-1 строка, задающие родителя для каждого элемента дерева, кроме корня.
Каждая строка имеет вид имя_потомка имя_родителя.
Программа должна сформировать словарь children и вывести его при помощи функции pprint из модуля pprint.
12
Alice Jake
Caitlin Jake
Adam Alice
Grace Alice
Jay Alice
Sean Alice
Ben Caitlin
Eva Ben
Harry Ben
Megan Ben
Luca Grace
Реализуйте функцию tree_from_input(),
считывающую информацию о строении дерева из стандартного ввода в формате из задач A и B,
и возвращающую тройку (root, parents, children).
Выведите результат её работы при помощи функции pprint.
Дано корневое дерево в формате из задач A и B.
В следующей строке вводится одна из вершин дерева.
Выведите количество сыновей этой вершины.
4
Alice Jake
Caitlin Jake
Grace Alice
Jake
2
IDE
E: Количество сыновей — 2
Дано корневое дерево в формате из задач A и B.
Выведите количество сыновей каждой вершины.
Список вершин должен быть отсортирован в лексикографическом порядке.
4
Alice Jake
Caitlin Jake
Grace Alice
Alice 1
Caitlin 0
Grace 0
Jake 2
IDE
F: Все листья в дереве
Дано корневое дерево в формате из задач A и B.
Выведите все его листья в лексикографическом порядке
4
Alice Jake
Caitlin Jake
Grace Alice
Caitlin
Grace
IDE
G: Все предки
Дано корневое дерево в формате из задач A и B.
В следующей строке вводится одна из вершин дерева.
Выведите всех предков этой вершины в порядке приближения к корню.
Каждому элементу дерева сопоставляется целое неотрицательное число, называемое высотой.
У корня высота равна 0, у любого другого элемента высота на 1 больше, чем у его родителя.
Программа должна вывести список всех элементов древа в лексикографическом порядке.
После вывода имени каждого элемента необходимо вывести его высоту.
Эта задача имеет решение сложности \(O(n)\), но вам достаточно написать решение сложности \(O(n^2)\) (не считая сложности обращения к элементам словаря).
4
Alice Jake
Caitlin Jake
Grace Alice
Alice 1
Caitlin 1
Grace 2
Jake 0
IDE
I°: Обход в глубину
Дано корневое дерево в формате из задач A и B и одна из его вершин.
Перечислите всех её потомков, включая саму вершину, в порядке обхода в глубину.
Стратегия обхода в глубину, как и следует из названия, состоит в том, чтобы идти «вглубь» дерева, насколько это возможно.
Алгоритм обхода описывается рекурсивно:
сначала выводим рассматриваемую вершину, а затем для каждого сына выполняем обход в глубину.
Конкретный порядок вершин в рамках обхода в глубину не важен и может отличаться от вывода в примере.
По-английски такой перебор называется Depth-First-Search, или DFS.
По умолчанию в питоне максимальная глубина рекурсии ограничена примерно вложенностью в 1000.
Её можно увеличить при помощи
from sys import *
setrecursionlimit(100000)
Как обычно, помнить эти команды не нужно, dir(sys) поможет найти нужную функцию.
Увеличивая глубину рекурсии следует помнить, что реальная максимальная глубина ограничена не только числом, переданным функции setrecursionlimit, но и ограничением операционной системы.
Скажем, в OS Windows это ограничение около нескольких тысяч.
12
Alice Jake
Caitlin Jake
Adam Alice
Grace Alice
Jay Alice
Sean Alice
Ben Caitlin
Eva Ben
Harry Ben
Megan Ben
Luca Grace
Jake
Jake
Alice
Adam
Grace
Luca
Jay
Sean
Caitlin
Ben
Eva
Harry
Megan
IDE
J°: Обход в ширину
Дано корневое дерево в формате из задач A и B и одна из его вершин.
Перечислите всех её потомков, включая саму вершину, в порядке обхода в ширину.
Стратегия обхода в ширину начинается с рассматриваемой вершины.
Затем перечисляются все её преемники, потом преемники этих преемников и т.д.
Таким образом перечисляются сначала все вершины на высоте 0, затем на высоте 1, и так далее.
Конкретный порядок вершин в рамках обхода в ширину не важен и может отличаться от вывода в примере.
По-английски такой перебор называется Breadth-First-Search, или BFS.
12
Alice Jake
Caitlin Jake
Adam Alice
Grace Alice
Jay Alice
Sean Alice
Ben Caitlin
Eva Ben
Harry Ben
Megan Ben
Luca Grace
Jake
Jake
Alice
Caitlin
Adam
Grace
Jay
Sean
Ben
Luca
Megan
Eva
Harry
Подсказка
Да, мне кажется, что я уже достаточно думал над этой задачей
Чес-слово! :)
Будем хранить два множества: множество элементов, которые необходимо обойти на текущем уровне дерева,
а также множество встреченных элементов следующего уровня.
Сначала добавляем в первое множество начальную вершину, а второе оставляем пустым.
Далее до тех пор, пока первое множество не иссякнет выполняем процедуру обхода:
для каждого элемента первого множества выводим его, после чего добавляем всех его потомков во второе множество.
После того, как все элементы первого множества будут обработаны, назначаем второе множество первым, а пустое множество — новым вторым.
IDE
K: Подсчёт высоты — 2
Решите задачу H за время \(O(n)\) (не считая сложности обращения к элементам словаря и сортировки).
4
Alice Jake
Caitlin Jake
Grace Alice
Alice 1
Caitlin 1
Grace 2
Jake 0
IDE
L: Предки и потомки
Даны два элемента в дереве. Определите, является ли один из них потомком другого.
Программа получает на вход описание дерева, как в задачах 01 и 02.
Далее идёт натуральное число M — количество запросов.
После этого идёт M строк, содержащие имена двух элементов дерева.
Для каждого такого запроса выведите одно из трех чисел: 1, если первый элемент является предком второго (или они совпадают), 2, если второй является предком первого или 0, если ни один из них не является предком другого.
4
Alice Jake
Caitlin Jake
Grace Alice
3
Alice Jake
Jake Alice
Alice Caitlin
2
1
0
IDE
M: Наименьший общий предок
Даны два элемента в дереве.
Определите для двух элементов их наименьшего общего предка.
Наименьшим общим предком элементов A и B является такой элемент C, что С является предком A, C является предком B,
и среди потомков C нет общих предков A и B.
При этом элемент считается своим собственным предком.
Формат входных данных аналогичен предыдущей задаче. Для каждого запроса выведите наименьшего общего предка данных элементов.
По-английски такая задача называется lowest common ancestor (LCA).
4
Alice Jake
Caitlin Jake
Grace Alice
3
Jake Jake
Grace Alice
Grace Caitlin
Jake
Alice
Jake
IDE
N: Число потомков
Для каждого элемента дерева определите число всех его потомков (не считая его самого).
Формат выходных данных совпадает с задачами 01 и 02.
Выведите список всех элементов в лексикографическом
порядке, для каждого элемента выводите количество всех его потомков.
Решение должно иметь сложность \(O(N)\), не считая сложности обращения к элементам словаря
и сортировки результата.
4
Alice Jake
Caitlin Jake
Grace Alice
Alice 1
Caitlin 0
Grace 0
Jake 3
IDE
O°: Обход в глубину без рекурсии
Реализуйте алгоритм обхода в глубину без использования рекурсии.
IDE
Метки времени при обходе в глубину
Метки времени — приём, который лежит в основе многих применений поиска в глубину.
Обычный алгоритм обхода в глубину описывается рекурсивно:
сначала выводим рассматриваемую вершину, а затем для каждого сына выполняем обход в глубину.
Метки времени — это натуральные числа от \(1\) до \(2|V|\).
Каждая вершина при обходе в глубину получает две метки: время начала обработки и время окончания,
причём все метки всех вершин различны.
Заведём счётчик времени.
Изначально счётчик равен нулю.
Каждый раз, когда мы переходим от одной вершины к другой мы прибавляем к счётчику единицу.
Время начала обработки — это значение счётчика в тот момент, когда мы «выводим рассматриваемую вершину».
Время окончания — это значение счётчика после того, как будет выполнен обход в глубину для всех сыновьих вершин.
Каждый раз, когда мы начинаем обход для какой-либо вершины, мы прибавляем 1 к счётчику.
Аналогично мы прибавляем 1 к счётчику после того, как закончили обход для данной вершины.
На картинке справа приведён обход в глубину с отметками времени.
Дополнительно простановку меток времени можно представлять себе так:
нарисуем дерево на плоскости, после чего обведём его пунктиром начиная с корня.
Каждый раз, когда наш пунктир проходит слева или справа от вершины, мы записываем число — порядковый номер встречи с вершиной.
Числа, записанные слева от каждой вершины будут временем начала обработки, числа справа — временем окончания.
Заметим сначала довольно банальное свойство меток времени:
если отсортировать все вершины по возрастанию времени начала обработки или по убыванию времени окончания обработки,
то получившийся порядок будет соответствовать некоторому обходу в глубину.
Следующее свойство — времена начала и окончания образуют правильную скобочную структуру.
Если мы в последовательности чисел от \(1\) до \(2|V|\) заменим числа, соответствующие меткам начала обработки на открывающую скобку,
а числа, соответствующие меткам окончания обработки на закрывающую, то в результате получится правильная скобочная структура.
Так в примере выше получается
\[
\mathbf{(\ (\ (\ )\ (\ )\ (\ )\ )\ (\ (\ (\ )\ )\ (\ )\ )\ )}
\]
Дальше: оказывается, по меткам времени очень легко понять, является ли одна вершина предком другой или наоборот.
Как? Ну, это вы сами должны догадаться.
Когда мы будем работать с более сложными графами, то увидим ещё несколько применений меткам времени.
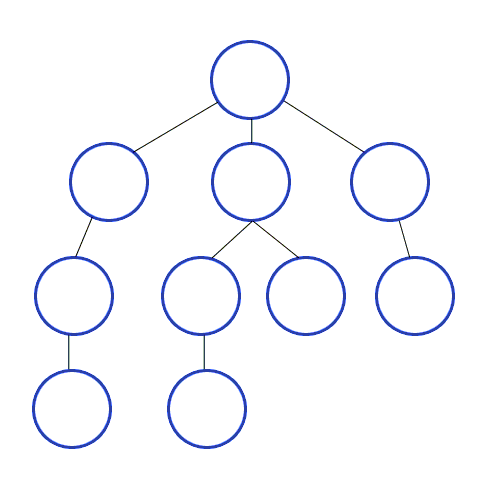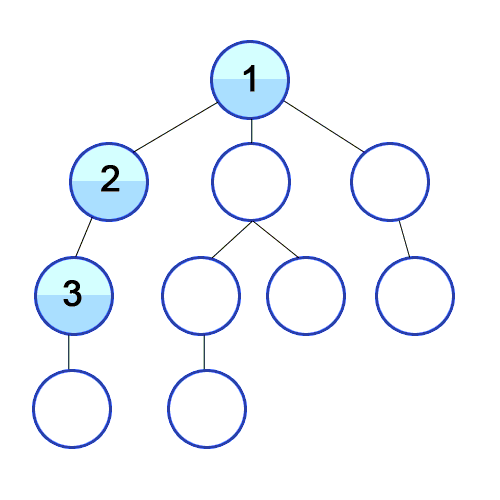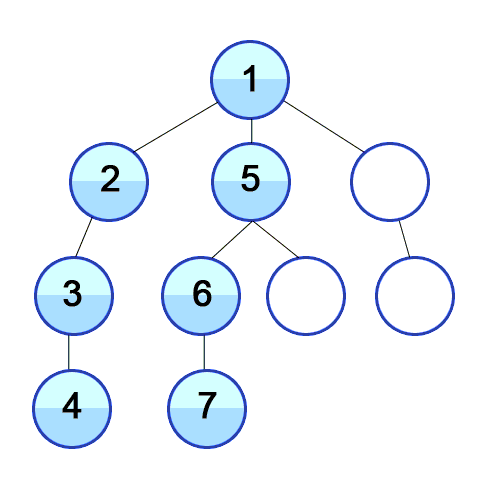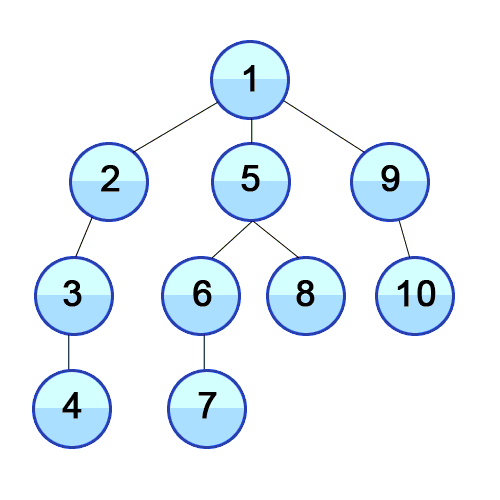
P: Метки времени при обходе в глубину дерева
На вход подаётся корневое дерево в формате задач A и B из предыдущего листка.
Выполните обход дерева в глубину начиная с корня и вычислите метки времени для вашего обхода.
Выведите вершины в лексикографическом порядке, указав для каждой вершины время начала и время окончания обработки.
(Конкретные времена зависят от обхода и могут не совпадать с временами в примере)
Для решения могут пригодиться глобальные переменные. Напоминание здесь.
Также метку времени можно хранить внутри одноэлементного списка, который создаётся в самом начале обхода, и передаётся в функцию при рекурсивных вызовах.
9
B A
C B
D B
E B
F A
G F
H G
I F
A 1 18
B 2 9
C 3 4
D 5 6
E 7 8
F 10 17
G 11 14
H 12 13
I 15 16
Подсказка
Да, мне кажется, что я уже достаточно думал над этой задачей
Чес-слово! :)
Для решения нужно "усилить" самый обычный рекурсивный обход в глубину.
Нужно создать глобальные переменные time=0, time_in={} и time_out={}.
В начале функции нужно прибавлять к времени 1 и заносить время в словарь time_in,
после обхода всех сыновьих вершин нужно прибавлять к времени 1 и заносить время в словарь time_out.
Несложно модифицировать и нерекурсивный алгоритм на основе стека.
Идея будет следующей: после того, как мы сняли вершину со стека, нужно проверить, если ли она в словаре time_in.
Если есть, то выбросить её и идти дальше. А если нет, то добавить метку времени, ещё раз добавить её в стек и начать обходить её сыновьи вершины.
После того, как все они будут обработаны, мы снова вернёмся к этой вершине и проставим время окончания обработки.
IDE
Q: Предки и потомки — 2
Даны два элемента в дереве. Определите, является ли один из них потомком другого.
Программа получает на вход описание дерева.
Далее идёт натуральное число M — количество запросов.
После этого идёт M строк, содержащие имена двух элементов дерева.
Для каждого такого запроса выведите одно из трех чисел: 1, если первый элемент является предком второго (или они совпадают), 2, если второй является предком первого или 0, если ни один из них не является предком другого.
Число M будет очень велико, поэтому каждая такая проверка должна требовать константу времени.
Для этого можно использовать метки времени из предыдущей задачи.
4
Alice Jake
Caitlin Jake
Grace Alice
3
Alice Jake
Jake Alice
Alice Caitlin
2
1
0
IDE
R: Обмен вершин
Дано дерево в формате из задач A и B, а также две его различные вершины.
Поменяйте местами в дереве эти вершины.
Выведите тройку (root, parents, children) для нового дерева при помощи pprint.
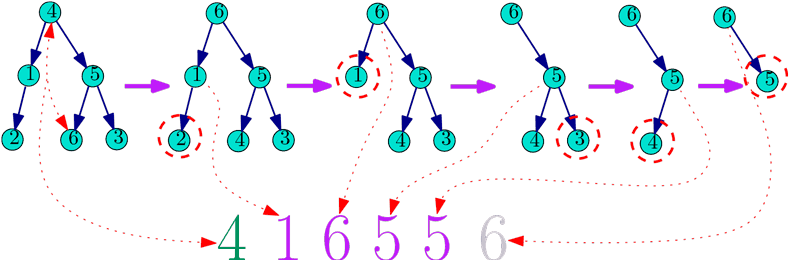
Оказывается, что корневых деревьев на \(n\) вершинах, пронумерованных числами от 1 до \(n\),
существует в точности \(n^{n-1}\).
Причём по каждому дереву можно за линейное время построить последовательность чисел от 1 до \(n\) длины \(n-1\),
и наоборот: по такой последовательности за линейное время восстановить отмеченное корневое дерево.
Код Прюфера — и есть способ такого кодирования.
На самом деле вместе с кодом Прюфера обычно рассматривают неукоренённые деревья (без отмеченного корня),
тогда код получается на 1 короче (длины \(n-2\) ).
Основная идея кодирования — поочерёдное удаление листьев из дерева в правильном порядке.
Для начала возьмём число, записанное в корне, пусть это число \(r\).
Это будет первый элемент кода (который отсутствует для неукоренённых деревьев).
После этого поменяем отметки \(r\) и \(n\) местами.
Для данного неукоренённого дерева существует в точности \(n\) способов выбрать корень,
поэтому в результате нашего действия мы всё свели к случаю, когда корень — это вершина с номером \(n\).
Теперь найдём лист с минимальным номером. Добавим в код номер его предка, после чего лист удалим из дерева.
Будем продолжать так до тех пор, пока в дереве не останется только две вершины (одна из которых — корень).
Временно забудем про первое число кода.
Тогда каждая вершина, кроме корня, появляется в коде ровно столько раз, сколько у неё потомков.
Сам корень будет участвовать в коде на один раз меньше (последний лист мы не удаляли, так как и так всё понятно.
Удаление последнего листа соответствует добавлению серой шестёрки на картинке).
Таким образом, листья дерева — в точности те числа, которые не встречаются в коде.
Когда мы строили код, первым числом был предок наименьшего листа.
Так как мы знаем все листья, то можем определить наименьший лист.
И из кода определяем предка этого листа.
После этого выбрасываем первое число из кода.
Теперь потенциальные листья — это числа, которые не встречаются в остатке кода,
и в которые при этом мы ещё не провели стрелку.
Дальше действуем точно также до окончания кода: находим минимальный потенциальный лист,
добавляем ребро. В конце нужно будет добавить ребро из корня в единственную вершину,
в которую ещё не проведена стрелка.
И наконец нужно поменять местами корень и то самое первое число кода, про которое мы специально забыли.
На вход программе подаётся дерево в формате задач A и B, вершины которого — числа от 1 до \(n\).
Выведите его код Прюфера.
6
2 1
1 4
6 5
3 5
5 4
4 1 6 5 5
IDE
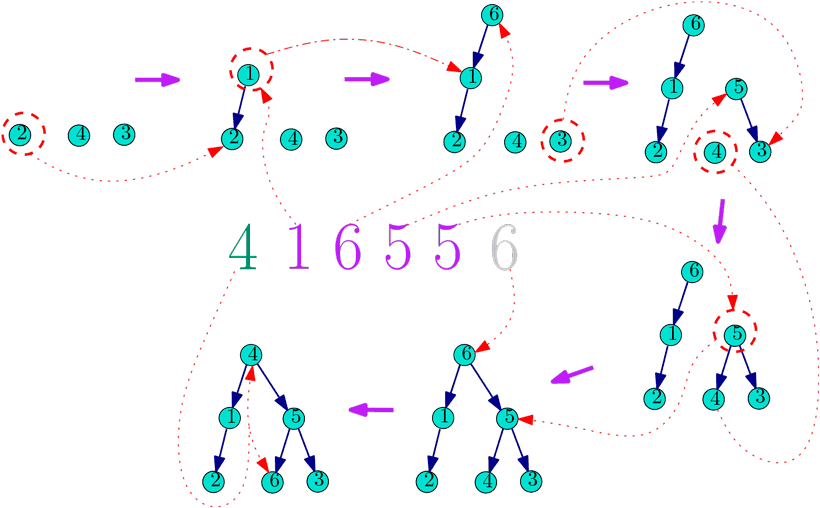
T★: Код Прюфера: Декодирование
На вход программе код Прюфера дерева, вершины которого — числа от 1 до \(n\).
Выведите в порядке возрастания родителя каждой вершины, кроме корня.
4 1 6 5 5
1 4
2 1
3 5
5 4
6 5
IDE
U★: Код Прюфера: доказательство
Докажите, что код Прюфера действительно позволяет построить биекцию между множеством отмеченных корневых деревьев с
\(n\) вершинами и множеством последовательностей чисел от 1 до \(n\) длины \(n-1\).
 Дано корневое дерево в формате из задач
Дано корневое дерево в формате из задач  Дано корневое дерево в формате из задач
Дано корневое дерево в формате из задач 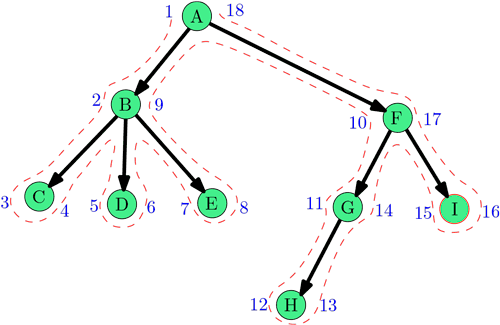 Метки времени — приём, который лежит в основе многих применений поиска в глубину.
Метки времени — приём, который лежит в основе многих применений поиска в глубину.