Реляционные базы данных
Практически во всех задачах, которые встречались нам ранее, данные поступали из стандартного ввода или из файла вроде input.txt.
Однако в реальных приложениях очень часто данные нужно хранить между запусками и периодически модифицировать.
В принципе данные можно хранить в простых текстовых файлах и обновлять их там же.
Или использовать библиотеки вроде pickle.
Но это не очень удобно и не слишком надёжно, если речь идёт о больших приложениях.
Понятие база данных — крайне общее. Это — совокупность данных, организованная так, чтобы они могли быть найдены и обработаны при помощи ЭВМ. Сейчас практически всегда, когда употребляется словосочетание «база данных», имеется в виду какой-нибудь конкретный подход для хранения и обработки данных, или даже конкретное ПО (конкретная «СУБД», система управления базами данных), которое всё это реализует.
В этой теме мы будем работать с реляционными базами данных.
«Реляционные» — это от слова relations — отношения.
Если забить на формализм, то суть подхода в следующем.
Существует ровно две сущности: элемент (value) и таблица (table).
Элемент — это какой-то кусочек данных, которые мы храним: число, строка, время и т.п.
Таблица — ну, это прямоугольная таблица, в которой есть строки и столбцы.
Множество столбцов (их имён и типов) называется заголовком таблицы.

При помощи таблиц можно хранить разнообразные отношения (relations), в том числе чертовски сложные. Например, вот так можно хранить граф:
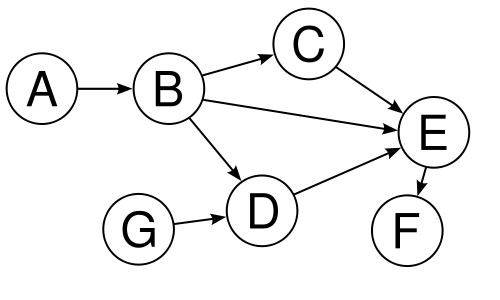
| node |
|---|
| A |
| B |
| C |
| D |
| E |
| F |
| G |
| from | to |
|---|---|
| A | B |
| B | C |
| B | D |
| B | E |
| C | E |
| D | E |
| E | F |
| G | D |
На множестве всех таблиц определены операции, которые все вместе называются «реляционной алгеброй». Вот список почти всех таких операций (тоже по модулю некоторого занудства):
- переименование таблицы — любую таблицу можно переименовать и получить новую таблицу с новым именем;
- переименование столбцов — если поменять в таблице имена столцбов, то тоже получится таблица;
- объединение таблиц — если у двух таблиц одинаковый заголовок (множество столбцов), то их можно объединить: в результате будет таблица с тем же заголовком, и множеством строк, в которой каждая либо лежит в первой, либо во второй таблице, либо в обеих;
- пересечение таблиц — если у двух таблиц одинаковый заголовок, то их можно пересечь: в результате будет таблица с тем же заголовком, и множеством строк, в которой каждая лежит и в первой, и во второй таблице;
- произведение таблиц — у получившийся таблицы будет суммарное количество столбцов, а строки — все возможные наборы, которые начинаются на строчку первой таблицы и заканчиваются на строку второй;
- выборка из таблицы — у любой таблицы можно взять подмножество строк. Получится таблица с тем же заголовком и частью строк;
- проекция таблицы — у любой таблицы можно взять подмножество столбцов, после чего удалить (или не удалять) дубликаты. Получится таблица, в котором меньше столбов, и столько же, либо меньше строк (из-за удаления дублей);
- добавление строк — в таблицу можно добавить новую строку с данными, и получить таблицу с тем же заголовком, но одной «бонусной» строкой;
- добавление столбцов — в таблицу можно добавить столбец с данным именем, значения которого в каждой строчке определяется функцией от значений во всех остальных столбцах данной строки.
- соединение таблиц — если у двух таблиц есть общие столбцы, то соединение таблиц — это новая таблица со всеми уникальными столбцами, строки которой «склеены» по совпадающим значениям общих столбцов. Эта операция — это композиция произведения, выборки и проекции: в произведении таблиц берём только те пары, где значения общих столбцов одинаковы. После чего удаляем общие столбцы;
Примеры всех этих операций будут дальше. Примечательно в них только то, что все они берут на вход одну или две таблицы и, может быть, какие-нибудь дополнительные данные, а на выходе всегда получают новую таблицу. Именно из-за замкнутости это всё называют «алгеброй».
SQL — язык структурированных запросов
Для того, чтобы формально описывать эти реляционные операции над таблицами, придуман специальный язык: SQL (Structured Query Language, язык структурированных запросов). У языка SQL есть некий стандарт (последняя версия ISO/IEC 9075:2016), однако конкретные «фразы» и богатство возможностей языка сильно зависят от конкретной реализации. Кроме реляционных операций язык позволяет создавать новые пустые таблицы с заданными столбцами, добавлять в таблицы новые записи, изменять и удалять строчки, изменять структуру таблиц, объявлять взаимосвязи между таблицами и т.п.
Вот примеры некоторых операций для типичной реализации SQL:
| Операция | Пример запроса |
|---|---|
| Создание таблицы | CREATE TABLE students (name TEXT, age NUMERIC); |
| Добавление строчки | INSERT INTO students VALUES ('Вася', 13), ('Маша', 14); |
| Запрос всех данных | SELECT * FROM students; |
| Объединение таблиц | SELECT * FROM students UNION SELECT * FROM students; |
| Пересечение таблиц | SELECT * FROM students INTERSECT SELECT * FROM students; |
| Произведение таблиц | SELECT * FROM students CROSS JOIN teachers; |
| Выборка из таблицы | SELECT * FROM students WHERE age < 14; |
| Проекция таблицы | SELECT age FROM students; |
| Добавление столбцов | SELECT students.*, age*365 as days FROM students; |
| Cоединение таблиц | SELECT * FROM students JOIN names USING (name); |
| Запрос данных с переимнованием | select stud.name as surname, stud.age as old from students as stud; |
| Переименование таблицы в базе | ALTER TABLE names RENAME TO names2; |
| Переименование столбцов в базе | ALTER TABLE names2 RENAME COLUMN name TO rname; |
SQLite
SQLite — это, пожалуй, самая распространённая СУБД — система управления базами данных. Коротко говоря, SQLite — это одна из программ, которая позволяет работать с базой данных и делать всё, описанное выше. Она очень компактна, быстра, и встроена почти всюду: в браузеры, телефоны, языки программирования и т.п. Её код передан в общественное достояние, она — одно из наиболее протестированного и надёжного ПО в мире.
Для экспериментов со своими данными удобнее всего установить sqlitebrowser. В питоне работа с SQLite находится в модуле sqlite3. Документация о всех командах, которые «понимает» SQLite на sqlite.org.
Запросы данных, ввод-вывод
Во всех задачах на подготовку запросов даётся база данных в db-файле (который при желании можно скачать). В каждой задаче нужно подготовить SQL-запрос, который решает поставленную задачу. И текст самого запроса необходимо сдать в проверяющую систему. Если запросов несколько, то они должны быть отделены точкой с запятой. Готовить запросы удобно во встроенной в эту страницу систему. (Только не пытайте использовать Internet Explorer, в нём работать не будет).
База «Студенты»
В первой части листка все забросы касаются базы «Школьники», в которой ровно одна таблица students:
| Имя столбца | Тип | Смысл |
|---|---|---|
| id | INTEGER | уникальный id школьника |
| name | TEXT | Имя школьника |
| surname | TEXT | Фамилия школьника |
| gender | TEXT | Пол: м/ж |
| age | INTEGER | Возраст, полных лет |
| avg_score | INTEGER | Средний балл |
| class | TEXT | Класс |
| classroom | TEXT | «Домашняя» аудитория |
| supervisor | TEXT | Классный руководитель |
| last_update | TIMESTAMP | Дата и время последнего изменения |
При необходимости скачать базу можно по ссылке. Первые 5 её строк выглядят так:
| id | name | surname | gender | age | avg_score | class | classroom | supervisor | last_update |
|---|---|---|---|---|---|---|---|---|---|
| 1 | Илларион | Осипов | м | 15 | 4.6596 | 10Б | 216 | Душин | 2019-02-16 10:02:48 |
| 2 | Педро | Лукин | м | 13 | 4.4163 | 8Д | 316 | Душин | 2019-04-05 23:41:22 |
| 3 | Гретель | Токарева | ж | 15 | 3.969 | 11Б | 306 | Юрков | 2019-05-15 02:50:09 |
| 4 | Марк | Пастухов | м | 12 | 4.7221 | 7В | 213 | Белоусов | 2019-03-19 05:00:54 |
| 5 | Мэлс | Круглов | м | 16 | 3.6567 | 10Б | 216 | Душин | 2019-04-07 18:38:47 |
Синтаксис SQL и syntax diagrams
Синтакс языка SQL удобно изображать при помощи диаграмм такого вида (они называются railroad diagrams):
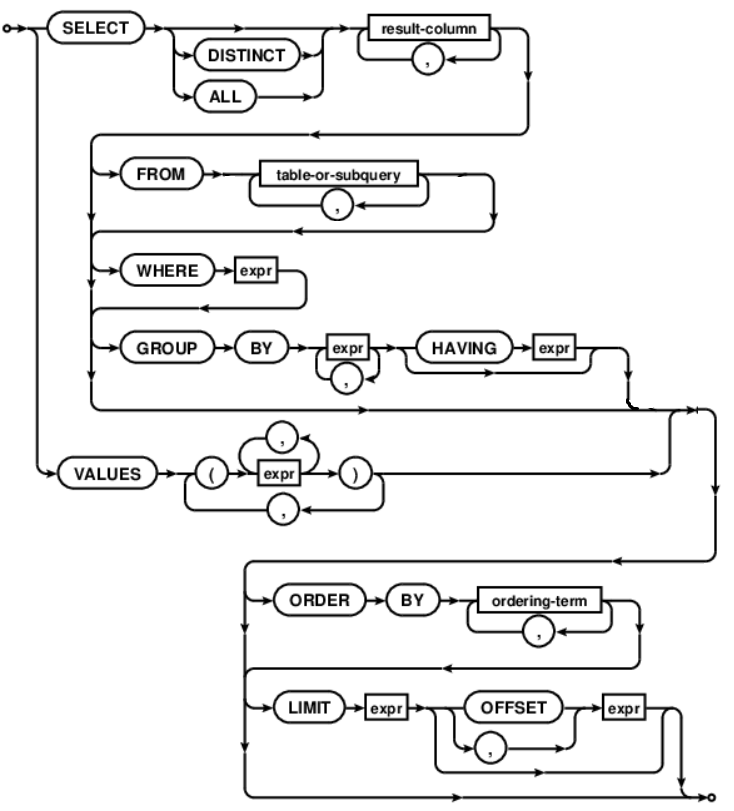
Чтобы получить валидный запрос, нужно пройти от начала до конца любым способом.
Более того, можно сделать такую схему, что только те запросы, которые получаются таким образом, будут валидными.
Их можно найти на sqlite.org/syntaxdiagrams.html.
Схема выше — упрощённая схема select-запроса (запрос данных).
Упражнение. Для каждого из запросов ниже пройдите по схеме и разберитесь, как это работает.
select name from students where surname = 'Шашков'
values ('Вася', 1), ('Коля', 2)select distinct class, case when supervisor = 'Шашков' then true else false end as godmode from students order by class
select class, max(height) from students group by class having count(*) > 10 order by 2 limit 10
Запросы на выборку данных из одной таблицы
A: Школьники из 9Б
Выведите фамилию и имя всех школьников из 9Б. В получившейся таблице должны быть два столбца и 24 строки.
Необходимые столцбы перечисляются после ключевого слова SELECT.
Условия отбора указываются после ключевого слова WHERE.
Первые 2 строчки ответа —
| surname | name |
|---|---|
| Карасев | Педро |
| Колосова | Елизавета |
Интерактивная отладка
B: Классные руководители
Выведите отсортированный список всех классных руководителей.
Для отбора чего-то уникального используется ключевое слово DISTINCT.
Для упорядочивания — ORDER BY.
При этом можно указывать либо выражения, по которым нужно сортировать, либо номера столбцов итоговой таблицы.
Первая строчка ответа —
| supervisor |
|---|
| Белоусов |
Интерактивная отладка
C: Никита, Антон и Алевтина
Выведите имя, фамилию, класс каждого школьника с именем Никита, Антон или Алевтина в порядке убывания среднего балла.
Для проверки принадлежности списку пригодится конструкция IN (..,..,..), она работает почти так же, как и в питоне, только .
Для обращения порядка сортировки — ключевое слово DESC. Первая строчка ответа —
| name | surname | class |
|---|---|---|
| Никита | Николаев | 7Д |
Интерактивная отладка
Даты и времена в sqlite
sqlite любит даты в формате YYYY-MM-DD, время в формате HH:MM:SS и timestamp'ы в формате YYYY-MM-DD HH:MM:SS.
(Ну, это если упростить. Вообще смотрите документацию)
Впрочем, сам sqlite хранит даты и времена как строки и не валидирует, что туда сохраняют.
Чтобы дату, время или timestamp создать из строки в правильном формате, нужно применить функцию date, time или datetime('now')
Чтобы извлечь из даты или времени какую-то часть, удобнее всего использовать функцию strftime,
которую мы уже видели в листке про даты.
Вот примеры её вызова (учтите, что она возвращает именно строку)):
VALUES ( strftime('%s','2004-01-01 02:34:56') )
VALUES ( strftime('%Y-%m-%d','2004-01-01 02:34:56') )
VALUES ( strftime(some_format, some_datetime_field) )
В шаблонах можно использовать следующие подстановки:
| Формат | Значение | Пример |
|---|---|---|
| %d | День месяца [01,31] | 01, 02, …, 31 |
| %H | Час (24-часовой формат) [00,23] | 00, 01, …, 23 |
| %j | День года [001,366] | 001, 002, …, 366 |
| %m | Номер месяца [01,12] | 01, 02, …, 12 |
| %M | Число минут [00,59] | 00, 01, …, 59 |
| %S | Число секунд [00,59] | 00, 01, …, 59 |
| %s | Число секунд c 1970-01-01 | 1072924496 |
| %w | Номер дня недели [0(Sunday),6] | 0, 1, …, 6 (0=воскресенье, 6=суббота) |
| %W | Номер недели в году (нулевая неделя начинается с понедельника) [00,53] | 00, 01, …, 53 |
| %Y | Год с веком | 0001, 0002, …, 2013, 2014, …, 9999 В linux'е год выводится без ведущих нулей! 1, 2, …, 2013, 2014, …, 9999 |
D: Изменения в мае
Выведите все столбцы по тем школьникам, у которых последнее изменение данных было в мае 2019 года. Упорядочьте по возрастанию даты-времени последнего изменения.
| id | name | surname | gender | age | avg_score | class | classroom | supervisor | last_update |
|---|---|---|---|---|---|---|---|---|---|
| 19 | Константин | Овсянников | м | 11 | 4.7653 | 7Д | 314 | Мухин | 2019-05-01 16:04:51 |
Интерактивная отладка
Работаем со строками
Лайкаем строки: поиск по шаблону
Если нужно проверить строку на равенстно, то мы используем... равенство.
Если нужно проверить строку на принадлежность списку, то мы так и пишем var in ('str1', 'str2', 'etc').
Но иногда нужно проверить, что строка удовлетворяет какому-нибудь шаблону.
Для этого используется ключевое слово LIKE:
select * from t where col LIKE 'some%likes __ hot'
_ — это один любой символ, % — любая последовательность символов.
Если вдруг вам нужно использовать процент или подчёркивание как сами символы, то нужно объявить экранирующий символ и их экранировать:
select * from t where col LIKE '% \% _ \_' ESCAPE '\'
Склейка строк и приведение типов
В отличие от питона в sql'е строки склеиваются при помощи оператора ||.
Любители использовать этот оператор для «или» страдают.
Чтобы сделать из чего-угодно строку, нужно писать CAST(strange AS TEXT).
Кстати, преобразования типов и других сортов устроены точно так же.
Полезные строковые функции
Кроме этого есть ещё пачка функций для работы со строками:
instr,
length,
lower,
ltrim,
replace,
rtrim,
substr,
trim,
upper.
Из неочевидного по имени: функция instr находит индекс первого вхождения второй строки-параметра внутри первой, если считать индексы с 1.
И 0, если не нашлось. А ещё функции upper и lower работают только с латиницей.
E: У кого в классе есть ***цев?
Выведите по порядку все классы, в которых есть школьник с фамилией, заканчивающейся на 'цев'. Должно получиться 4 уникальных класса.
Интерактивная отладка
F: Пришли мне json'ы с фамилиями!
Нет времени объяснять. Нужны фамилии и возраста тех, у кого в фамилии ровно 10 букв. Результаты склеить в json'ы и отсортировать. Первая строчка ниже, добудь мне их все!
| json |
|---|
| {"surname": "Андрианова", "age": 13} |
Интерактивная отладка
Группировка и агрегирующие функции
Агрегирование
Часто бывает такое, что вместо самих данных нужны какие-нибудь их агрегаты.
Например, количество, сумма, минимум, максимум или среднее значение.
Это позволяют сделать функции
avg,
count,
group_concat,
max,
min,
sum.
Вот документация по всем агрегирующим функциям.
Использовать их очень просто:
select count(*), sum(age), min(avg_score), count(distinct classroom), group_concat(distinct name) -- Прикиньте, все уникальные имена склеит! from students
Группировка
А что если такую штуку нужно выполнить, скажем, для каждого класса? 30 запросов выполнять? Вот чтобы ответ на этот вопрос был «нет» существует ещё и группировка. Если забить на занудство и порядок столбцов, то синтаксис такой:
select field1, field2, sum(field3), avg(field4) from table where field5 between 1 and 5 group by field1, field2 -- В sqlite можно писать и короче: group by 1, 2
В результате этого запроса суммирование будет производиться только по записям с данными значениями первых двух полей. Обратите внимание: сначала идёт отбор, затем группировка.
Последующий отбор
Отбор при помощи WHERE производится до группировки.
Если нужно выбросить лишние записи после группировки, то это делается при помощи ключевого слова HAVING.
Получается что-то в духе
select country, sum(money) from cities group by country having count(*) > 10 and sum(money) > 1000000000000
G: Сколько же школьников в этой школе??
И действительно, сколько? Ну, вернее в этой базе. Говорят, это какое-то красивое число, 4-я степень.
Интерактивная отладка
H: Средний средний балл
Что может быть разумнее, чем посчитать среднее значение средних баллов? Для каждого класса выведите округлённое до 2 знаков после запятой среднее значение среднего балла школьников этого класса. И упорядочьте по убыванию этого среднего. Каким-то образом там 10Е всех рвёт с результатом 4.32:
| class | avgavg |
|---|---|
| 10Е | 4.32 |
Да-да, round в sqlite работает примерно также, как и в питоне.
Интерактивная отладка
I: У кого какие классы
Для каждого классного руководителя выведите число его классов и их список. Результат начинается со строчки
| supervisor | cnt | lst |
|---|---|---|
| Белоусов | 2 | 7В,10В |
Интерактивная отладка
J: В каких классах много девочек?
Для каждого класса нужно посчитать число девочек. Нужны только те классы, где их хотя бы 8. Упорядочить по классу, но чур «нормально»: сначала 7 классы, в конце — 11:
| class | count(*) |
|---|---|
| 7Б | 8 |
Подсказка
А-а-а! Как это сделать?
Здесь пригодятся count(*), group by, having, cast, substr, length,
numeric.
И да, для сортировки в питоне бы мы написали sort(key=lambda cls: (int(cls[:-1]), cls)).
Но в SQL нет срезов, индексы начинаются с 1, и -1 в качестве индекса не сработает, придётся считать самостоятельно.
Интерактивная отладка
Подзапросы
Хитрые where
Иногда нужно отобрать какие-нибудь особенно интересные записи. Но чтобы оценить интересность, нужно выполнить ещё один запрос. Так вот, это можно делать:
select * from table -- поле равно таблице с 1 строкой и 1 столбцом where fld = (select max(fld) from table) -- поле лежит в таблице с 1 столбцом or fld in (select 'foo' || id from table where some=other) -- несколько полей равны таблице с 1 строкой и соответствующим числом столбцов or (fld1, fld2) = (select min(fld1), max(fld2) from table limit 1) -- строка из нескольких полей лежит в таблице с соответствующим числом столбцов or (fld1, fld2) in (select fld1 * fld1, fld1 + fld2 from table)
В поздапросе можно использовать имена столбцов из основного запроса.
Но если имена столбцов совпадают, то нужно указывать, о какой таблице идёт речь в формате таблица.поле:
SELECT name, result FROM students
WHERE result = (SELECT Max(result) FROM results
WHERE students.name = results.name) -- вот здесь разные поля с одним именем
Если имена таблиц при этом одинаковы, то эти имена нужно поменять:
select name, result from students as main -- Можно использовать любое имя или не добавлять вовсе
where result = (select max(result) from students as sub
where sub.name = main.name) -- <-- Вот здесь одинаковые имена стали разными
Таблица как поле
А ещё если результат подзапроса — таблица 1 × 1, то её можно использовать в любом месте на равне с именами полей и прочими выражениями:
select col, (select foo from boo limit 1) from table where (select zoo from moo where doo = col) = mol order by (select goo from boo limit 1)
Каскады
Ещё один частый сценарий использования подзапросов — это последовательная обработка и агрегирование:
SELECT supervisor, Avg(cnt)
FROM (SELECT class, supervisor, Count(*) AS cnt
FROM students
GROUP BY class, supervisor)
GROUP BY supervisor
K: Лучший в каждом классе
Найдите в каждом классе самого успешного школьника.
Упорядочьте по убыванию среднего балла.
Первые 3 строчки результата:
| class | surname | name | avg_score |
|---|---|---|---|
| 8Г | Серова | Ксения | 4 .9929 |
| 8Е | Карасев | Патрик | 4.9914 |
| 8Д | Ананьев | Феликс | 4.9898 |
Интерактивная отладка
L: Среднее число школьников у классруков
Для каждого классного руководителя посчитайте среднее число школьников в его классах. Упорядочьте по имени руководителя.
| supervisor | Avg(cnt) |
|---|---|
| Белоусов | 29 |
| Дориченко | 26 .666666666666668 |
| Душин | 26.25 |
Интерактивная отладка
M: Число школьников в школе с меньшим баллом
Для каждого школьника из 9Б посчитайте, сколько школьников имеют средний балл строго меньше. Упорядочьте по убыванию среднего балла.
| class | surname | name | avg_score | better |
|---|---|---|---|---|
| 9Б | Козырева | Дана | 4.9567 | 612 |
| 9Б | Горячев | Хасан | 4.9404 | 606 |
| 9Б | Гордеева | Фатима | 4.9315 | 602 |
Интерактивная отладка
Обобщенные табличные выражения (CTE) (with ... as () ...)
Оконные функции
База «Расписание»
Во второй части листка все запросы касаются базы «Расписание», состоящей из нескольких таблиц.