В языке Python 3 строки — это строки последовательности юникодных символов.
Для обозначения конкретной строки в программе можно использовать одну из четырёх возможных конструкций:
a = 'В этой строке можно использовать символ ", а обычную кавычку нужно экранировать'
b = "Здесь можно писать ', но \" нужно экранировать: \" "
с = '''Строка на
несколько строк (можно писать ' и " свободно)'''
d = """То же самое, только кавычки другие \
нужно использовать \, чтобы экранировать конец строки"""
Конечно же, строки можно также получать из других типов приведением к строке, а также получать из внешних источников.
Строка считывается со стандартного ввода функцией input(). Напомним,
что для двух строк определа операция сложения (конкатенации), также определена
операция умножения строки на число.
Строка состоит из последовательности символов. Узнать количество символов (длину строки)
можно при помощи функции len:
>>> S = 'Hello'
>>> print(len(S))
5
Срезы (slices)
Срез (slice) — извлечение из данной строки одного символа или некоторого фрагмента
подстроки или подпоследовательности.
Есть три формы срезов. Самая простая форма среза: взятие одного символа
строки, а именно, S[i] — это срез, состоящий из одного символа,
который имеет номер i, при этом считая, что нумерация начинается
с числа 0. То есть если S='Hello', то
S[0]=='H', S[1]=='e', S[2]=='l',
S[3]=='l', S[4]=='o'.
Номера символов в строке (а также в других структурах данных: списках, кортежах)
называются индексом.
Если указать отрицательное значение индекса, то номер будет отсчитываться
с конца, начиная с номера -1. То есть S[-1]=='o',
S[-2]=='l', S[-3]=='l', S[-4]=='e',
S[-5]=='H'.
Или в виде таблицы:
Строка S
H
e
l
l
o
Индекс
S[0]
S[1]
S[2]
S[3]
S[4]
Индекс
S[-5]
S[-4]
S[-3]
S[-2]
S[-1]
Если же номер символа в срезе строки S больше либо равен len(S),
или меньше, чем -len(S), то при обращении к этому символу строки произойдет
ошибка IndexError: string index out of range.
Срез с двумя параметрами: S[a:b]
возвращает подстроку из b-a символов,
начиная с символа c индексом a,
то есть до символа с индексом b, не включая его.
Например, S[1:4]=='ell', то же самое получится
если написать S[-4:-1]. Можно использовать как положительные,
так и отрицательные индексы в одном срезе, например, S[1:-1] —
это строка без первого и последнего символа (срез начинается с символа с индексом 1 и
заканчиватеся индексом -1, не включая его).
При использовании такой формы среза ошибки IndexError
никогда не возникает. Например, срез S[1:5]
вернет строку 'ello', таким же будет результат,
если сделать второй индекс очень большим, например,
S[1:100] (если в строке не более 100 символов).
Если опустить второй параметр (но поставить двоеточие),
то срез берется до конца строки. Например, чтобы удалить
из строки первый символ (его индекс равен 0, то есть
взять срез, начиная с символа с индексом 1), то можно
взять срез S[1:], аналогично
если опустиить первый параметр, то срез берется от начала строки.
То есть удалить из строки последний символ можно при помощи среза
S[:-1]. Срез S[:] совпадает с самой строкой
S.
Если задать срез с тремя параметрами S[a:b:d],
то третий параметр задает шаг, как в случае с функцией
range, то есть будут взяты символы с индексами
a, a+d, a+2*d и т.д.
При задании значения третьего параметра, равному 2, в срез попадет
кажый второй символ, а если взять значение среза, равное
-1, то символы будут идти в обратном порядке.
Методы строк
Метод — это функция, применяемая к объекту, в данном случае — к строке.
Метод вызывается в виде Имя_объекта.Имя_метода(параметры).
Например, S.find("e") — это применение к строке S
метода find с одним параметром "e".
Метод find и rfind
Метод find находит в данной строке (к которой применяется метод)
данную подстроку (которая передается в качестве параметра).
Функция возвращает индекс первого вхождения искомой подстроки.
Если же подстрока не найдена, то метод возвращает значение -1. Например:
Аналогично, метод rfind возвращает индекс последнего вхождения
данной строки («поиск справа»).
>>> S = 'Hello'
>>> print(S.find('l'))
2
>>> print(S.rfind('l'))
3
Если вызвать метод find с тремя параметрами
S.find(T, a, b), то поиск будет осуществляться
в срезе S[a:b]. Если указать только два параметра
S.find(T, a), то поиск будет осуществляться
в срезе S[a:], то есть начиная с символа с индексом
a и до конца строки. Метод S.find(T, a, b)
возращает индекс в строке S, а не индекс относительно
начала среза.
Метод replace
Метод replace заменяет все вхождения одной строки на другую. Формат:
S.replace(old, new) — заменить в строке S
все вхождения подстроки old на подстроку new. Пример:
>>> 'Hello'.replace('l', 'L')
'HeLLo'
Если методу replace задать еще один параметр: S.replace(old, new, count),
то заменены будут не все вхождения, а только не больше, чем первые count из них.
Подсчитывает количество вхождений одной строки в другую строку. Простейшая
форма вызова S.count(T) возвращает число вхождений строки
T внутри строки S. При этом подсчитываются только
непересекающиеся вхождения, например:
При указании трех параметров S.count(T, a, b),
будет выполнен подсчет числа вхождений строки T
в срез S[a:b].
Методы startswith и endswith, проверка наличия подстроки
В тех случаях, когда нужно проверить, что строка начинается или заканчивается некоторой подстрокой,
то вместо срезов принято использовать методы startswith и endswith:
Для проверки наличия подстроки кроме метода find можно использовать простую конструкцию:
>>> 'acad' in 'Abracadabra'
True
Упражнения
A: Делаем срезы
Дана строка.
Сначала выведите третий символ этой строки.
Во второй строке выведите предпоследний символ этой строки.
В третьей строке выведите первые пять символов этой строки.
В четвертой строке выведите всю строку, кроме последних двух символов.
В пятой строке выведите все символы с четными индексами (считая, что индексация начинается с 0, поэтому символы выводятся начиная с первого).
В шестой строке выведите все символы с нечетными индексами, то есть начиная со второго символа строки.
В седьмой строке выведите все символы в обратном порядке.
В восьмой строке выведите все символы строки через один в обратном порядке, начиная с последнего.
В девятой строке выведите длину данной строки.
Абракадабра
р
р
Абрак
Абракадаб
Аркдба
бааар
арбадакарбА
абдкрА
11
IDE
B: Количество слов
Дана строка, состоящая из слов, разделенных пробелами. Определите, сколько в ней слов.
Используйте для решения задачи метод count.
Hello world
2
IDE
C: Две половинки
Дана строка. Разрежьте ее на две равные части (если длина строки — четная, а если
длина строки нечетная, то длина первой части должна быть на один символ больше). Переставьте
эти две части местами, результат запишите в новую строку и выведите на экран.
При решении этой задачи нельзя пользоваться инструкцией if.
Hi
iH
Hello
loHel
IDE
D: Переставить два слова
Дана строка, состоящая ровно из двух слов, разделенных пробелом. Переставьте эти слова
местами. Результат запишите в строку и выведите получившуюся строку.
При решении этой задачи нельзя пользоваться циклами и инструкцией if.
Hello world
world Hello
IDE
E: Первое и последнее вхождение
Дана строка. Если в этой строке буква f встречается
только один раз, выведите её индекс. Если она встречается два и более раз,
выведите индекс её первого и последнего появления. Если буква
f в данной строке не встречается, ничего не выводите.
При решении этой задачи нельзя использовать метод count и циклы.
comfort
3
office
1 2
IDE
F: Второе вхождение
Дана строка. Найдите в этой строке второе вхождение
буквы f, и выведите индекс этого вхождения. Если
буква f в данной строке встречается только один
раз, выведите число -1, а если не встречается
ни разу, выведите число -2.
При решении этой задачи нельзя использовать метод count. Метод find
(а также rfind) можно вызывать не более двух раз. Для решения этой задачи нельзя использовать циклы.
comfort
-1
coffee
3
IDE
G: Удаление фрагмента
Дана строка, в которой буква h встречается минимум два раза.
Удалите из этой строки первое и последнее вхождение буквы h,
а также все символы, находящиеся между ними.
Методом replace пользоваться нельзя.
In the hole in the ground there lived a hobbit
In tobbit
IDE
H: Обращение фрагмента
Дана строка, в которой буква h встречается
как минимум два раза. Разверните последовательность символов,
заключенную между первым и последнием появлением буквы
h, в противоположном порядке.
Методом replace пользоваться нельзя.
In the hole in the ground there lived a hobbit
In th a devil ereht dnuorg eht ni eloh ehobbit
IDE
I: Дублирование фрагмента
Дана строка, в которой буква h встречается
как минимум два раза. Повторите последовательность символов,
заключенную между первым и последнием появлением буквы
h два раза, сами буквы h повторять не надо.
Методом replace пользоваться нельзя.
In the hole in the ground there lived a hobbit
In the hole in the ground there lived a e hole in the ground there lived a hobbit
IDE
J: Замена подстроки
Дана строка. Замените в этой строке все цифры 1 на слово
one.
1+1=2
one+one=2
IDE
K: Удаление символа
Дана строка. Удалите из этой строки все символы @.
Bilbo.Baggins@bagend.hobbiton.shire.me
Bilbo.Bagginsbagend.hobbiton.shire.me
IDE
L: Замена внутри фрагмента
Дана строка. Замение в этой строке все появления буквы h
на букву H, кроме первого и последнего вхождения.
In the hole in the ground there lived a hobbit
In the Hole in tHe ground tHere lived a hobbit
IDE
M: Вставка символов
Дана строка. Получите новую строку, вставив между каждыми соседними символами
исходной строки символ *. Выведите полученную строку.
Python
P*y*t*h*o*n
IDE
N: Удалить каждый третий символ
Дана строка. Удалите из нее все символы, чьи индексы делятся на 3.
Python
yton
IDE
O: Метод бутерброда
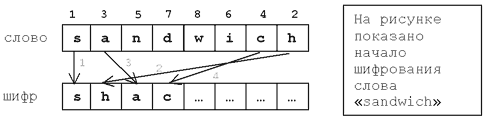
Секретное агентство решило для шифрования переписки своих сотрудников использовать «метод бутерброда».
Сначала буквы слова нумеруются в таком порядке: первая буква получает номер 1, последняя буква — номер 2,
вторая – номер 3, предпоследняя – номер 4, потом третья … и так для всех букв (см. рисунок).
Затем все буквы записываются в шифр в порядке своих номеров. Например, слово «sandwich» зашифруется в «shacnidw».
К сожалению, программист агентства, написал только программу шифрования и уволился.
И теперь агенты не могут понять, что же они написали друг другу. Помогите им.
Вводится слово, зашифрованное методом бутерброда. Выведите расшифрованное слово.
Aabrrbaacda
Abracadabra
IDE
16★: Маски имен файлов
Для групповых операций с файлами используются маски имён файлов. Маска представляет собой последовательность букв,
цифр и прочих допустимых в именах файлов символов, в которой также могут встречаться следующие символы.
Символ «?» (вопросительный знак) означает ровно один произвольный символ.
Символ «*» (звёздочка) означает любую последовательность символов произвольной длины, в том числе «*» может задавать и пустую последовательность.
Напишите программу, которая для каждого имени файла определит, подходит ли оно под заданную маску.
Гарантируется, что в маске файла присутствует не более одного символа «*».
В первой строке содержится маска файла. В следующей строке содержится имя файла по одному в строке.
Имя файла состоят из маленьких латинских букв, цифр и символа «.» (точка), в маске также могут содержаться символы «?» и «*»
(символ «*» — не более одного раза).
Выведите слово «YES» если оно удовлетворяет маске и «NO» иначе.
?or*.d??
fort.doc
YES
?or*.d??
ford.doc
YES
?or*.d??
lord2.doc
YES
?or*.d??
orsk.dat
NO
?or*.d??
port
NO
Другие методы строк
Функция
Описание
Пример
Строчные/прописные
str.capitalize
Переводит первый символ строки в верхний регистр, а все остальные в нижний
>>> 'привет, МИР!'.capitalize()
'Привет, мир!'
str.lower
Преобразование строки к нижнему регистру
>>> 'Странная ФУНКция'.lower()
'странная функция'
str.swapcase
Переводит символы нижнего регистра в верхний, а верхнего – в нижний
Первую букву каждого слова переводит в верхний регистр, а все остальные в нижний
>>> 'Странная ФУНКция'.title()
'Странная Функция'
str.upper
Преобразование строки к верхнему регистру
>>> 'Странная ФУНКция'.upper()
'СТРАННАЯ ФУНКЦИЯ'
Обрезка и выравнивание
str.center(width, [fill])
Возвращает отцентрованную строку, по краям которой стоит символ fill (пробел по умолчанию)
>>> 'xxx'.center(7)
' xxx '
str.ljust(width, fillchar=" ")
Делает длину строки не меньшей width, по необходимости заполняя последние символы символом fillchar. Также есть метод rjust, выравнивающий по правому краю
Делает длину строки не меньшей width, по необходимости заполняя первые символы нулями
>>> '123'.zfill(5)
'00123'
str.strip([chars])
Удаление пробельных символов в начале и в конце строки, либо символов из параметра chars, если он передан. Также есть команды lstrip и rstrip, удаляющие символы только слева или только справа
>>> ' foo bo zooo '.strip()
'foo bo zooo'
>>> '( ни за что!:-))'.strip('()-: ')
'ни за что!'
Проверка типа строки
str.isalnum
Состоит ли строка из букв и цифр
>>> 'Wy7'.isalnum()
True
str.isalpha
Состоит ли строка из букв
>>> 'Wy7'.isalpha()
False
str.isdigit
Состоит ли строка из цифр
>>> '12313'.isdigit()
True
str.islower
Состоит ли строка из символов в нижнем регистре
>>> 'привет, мир'.islower()
True
str.isspace
Состоит ли строка из неотображаемых символов (пробел, табуляция, перенос строки и т.п.)
>>> ' \n\t\r'.isspace()
True
str.isupper
Состоит ли строка из символов в верхнем регистре
>>> 'ПРИВЕТ, МИР'.isupper()
True
Нарезка и склейка строк
str.join
Склеивает все строки из переданного параметра, используя соединитель (возможно, пустой)
Разрезать строку по пробельным символам. Если указан sep, то по символам sep. Если указан maxsplit, то нарезается не более, чем на указанное количество кусков. Также есть метод rsplit, который выдаст не более maxsplit кусков, считая справа
Они включают себя только ASCII символы, поэтому разные тонкие вещи с юникодом решать не помогут.
Форматирование строк. Метод format
Иногда (а точнее, довольно часто) возникают ситуации, когда нужно сделать строку, подставив в неё некоторые данные, полученные в процессе выполнения программы (пользовательский ввод, данные из файлов и т. д.).
В этом случае для подстановки этих значений можно использовать строковый метод format.
При этом в шаблоне в места подстановок нужно поставить якори вида {}, а в параметры format передать ровно необходимое количество значений.
Однако возможностей у format гораздо больше: кроме непосредственной подстановки в строку возможно применение форматирования в выводимым данным.
Полный список возможностей можно получить непосредственно в документации,
а здесь будет список разумных примеров использования этого метода:
>>> '{}, {}, {}'.format('a', 'b', 'c')
'a, b, c'
>>> '{0}, {1}, {2}'.format('a', 'b', 'c') # Можно явно указать индексы
'a, b, c'
>>> '{2}, {1}, {0}'.format('a', 'b', 'c') # Если индексы указаны явно, то они могут идти в любом порядке
'c, b, a'
>>> '{0}{1}{0}'.format('abra', 'cad') # И даже повторяться
'abracadabra'
>>> 'Coordinates: {lat}, {lon}'.format(lat='37.24N', lon='-115.81W') # Можно вместо индексов явно указывать имена
'Coordinates: 37.24N, -115.81W'
# Выравнивания
>>> '{:<30}'.format('left aligned')
'left aligned '
>>> '{:>30}'.format('right aligned')
' right aligned'
>>> '{:^30}'.format('centered')
' centered '
>>> '{:*^30}'.format('centered') # Используем * для заполнения
'***********centered***********'
# Особый вывод действительных чисел
>>> '{:+f}; {:+f}'.format(3.14, -3.14) # Всегда показывать знак
'+3.140000; -3.140000'
>>> '{: f}; {: f}'.format(3.14, -3.14) # Или выводить пробел, если знака плюса нет
' 3.140000; -3.140000'
>>> '{:0.2f}; {:0.3f}; {:8.3f}'.format(3.14, -3.14, 179e-4) # Можно выводить фиксированное кол-во значащих цифр
'3.14; -3.140; 0.018'
# Вывод в двоичной, восьмеричной или шестнадцатиричной системе счисления
>>> "int: {0:d}; hex: {0:x}; oct: {0:o}; bin: {0:b}".format(42)
'int: 42; hex: 2a; oct: 52; bin: 101010'
>>> "int: {0:d}; hex: {0:#x}; oct: {0:#o}; bin: {0:#b}".format(42) # С префиксом 0x, 0o, 0b
'int: 42; hex: 0x2a; oct: 0o52; bin: 0b101010'
f-строки
Начиная с Python 3.6 появился ещё один способ получения строк, в которые вставлены значения некоторых переменных. Кроме того, что этот способ очень хорошо читается, он ещё и самый быстрый.
Начнём с примера:
>>> x = 10
>>> y = 5
>>> print(f"{x} x {y} / 2 = {x * y / 2}")
>>> 10 x 5 / 2 = 25.0
>>> planets = ["Меркурий", "Венера", "Земля", "Марс"]
>>> print(f"Мы живём не планете {planets[2]}")
>>> Мы живём не планете Земля
В целом этот подход очень похож на использование метода .format, только необходимо всегда указывать префикс f перед строкой и имена переменных внутри фигурных скобок.
Возможностей того, что можно указывать внутри фигурных скобок достаточно много: pep-0498.
Задачи на форматирование строк
Q★: Пять цифр после запятой
На вход даются десятичные числа.
Необходимо вывести их с в точность 5 цифрами после запятой.
На вход даётся число N — количество десятичный цифр,
затем следуют N действительных чисел.
3
-2
12.123
12.123456
-2.00000
12.12300
12.12346
IDE
R★: Фиксированное число цифр после запятой
На вход даются десятичные числа.
Необходимо вывести их с указанным числом цифр после запятой.
На вход даётся число d — количество знаков, после запятой, которые нужно выводить.
Затем идёт число N — количество чисел, после следуют N действительных чисел.
3
2
-12
12.1234
-12.000
12.123
IDE
S★: Таблица степеней — 1
На вход даётся число N.
Необходимо вывести таблицу квадратов и кубов.
Числа в таблице должны быть выровнены по правому краю.
Ширина каждого столбца — 10 символов.
3
| 0| 0| 0|
| 1| 1| 1|
| 2| 4| 8|
| 3| 9| 27|
IDE
T★: Таблица степеней — 2
На вход даётся число N.
Необходимо вывести таблицу квадратов и кубов.
Числа в таблице должны быть выровнены по правому краю.
Ширина каждого столбца должна быть минимальной, но так, чтобы все числа поместились.
На вход даётся числа d и N.
Необходимо вывести таблицу степеней от 1 до d чисел от 0 до N.
Числа в таблице должны быть выровнены по правому краю.
Ширина каждого столбца должна быть минимальной, но так, чтобы все числа поместились.
Дан ребус — таблица 5 × 5, заполненная буквами так, что в каждой строке, столбце и на каждой диагонали все буквы различны.
Нужно заменить его на другой ребус.
Для этого каждая буква ребуса заменяется на другую соответствующую букву.
Строка для замены букв даётся сразу после ребуса.