Множество в языке Питон — это структура данных, эквивалентная множствам в математике. Множество может состоять из различных элементов, порядок элементов в множестве неопределен. В множество можно добавлять и удалять элементы, можно перебирать элементы множества, можно выполнять операции над множествами (объединение, пересечение, разность). Можно проверять принадлежность элементу множества.
В отличии от массивов, где элементы хранятся в виде последовательного списка, в множествах порядок хранения элементов неопределен (более того, элементы множества храняться не подряд, как в списке, а при помощи хитрых алгоритмов). Это позволяет выполнять операции типа “проверить принадлежность элемента множеству” быстрее, чем просто перебирая все элементы множества.
Элементами множества может быть любой неизменяемый тип данных: числа, строки, кортежи. Изменяемые типы данных не могут быть элементами множества, в частности, нельзя сделать элементом множества список (но можно сделать кортеж) или другое множество. Требование неизменяемости элементов множества накладывается особенностями представления множества в памяти компьютера.
Множество задается перечислением всех его элементов в фигурных скобках. Например:
A = {1, 2, 3}
Исключением явлеется пустое множество, которое можно создать при помощи
функции set(). Если функции set передать в качестве
параметра список, строку или кортеж, то она вернет множество, составленное из элементов
списка, строки, кортежа. Например:
A = set('qwerty')
print(A)
выведет {'e', 'q', 'r', 't', 'w', 'y'}.
Каждый элемент может входить в множество только один раз, порядок задания элементов не важен. Например, программа:
A = {1, 2, 3}
B = {3, 2, 3, 1}
print(A == B)
выведет True, так как A и B — равные
множества.
Каждый элемент может входить в множество только один раз. set('Hello')
вернет множество из четырех элементов: {'H', 'e', 'l', 'o'}.
Узнать число элементов в множестве можно при помощи функции len.
Перебрать все элементы множества (в неопределенном порядке!) можно при помощи цикла for:
C = {1, 2, 3, 4, 5}
for elem in C:
print(elem)
Проверить, принадлежит ли элемент множеству можно при помощи операции
in, возвращающей значение типа bool:
i in A
Аналогично есть противоположная операция not in.
Для добавления элемента в множество есть метод add:
A.add(x)
Для удаления элемента x из множества есть два метода:
discard и remove. Их поведение различается
только в случае, когда удаляемый элемент отсутствует в множестве.
В этом случае метод discard не делает ничего, а метод
remove генерирует исключение KeyError.
Наконец, метод pop удаляет из множества один случайный
элемент и возвращает его значение. Если же множество пусто, то генерируется
исключение KeyError.
Из множества можно сделать список при помощи функции list.
При помощи цикла for можно перебрать все элементы множества:
Primes = {2, 3, 5, 7, 11}
for num im Primes:
print(num)
С множествами в питоне можно выполнять обычные для математики операции над множествами.
A | B A.union(B) |
Возвращает множество, являющееся объединением множеств A и B.
|
A |= B A.update(B) |
Добавляет в множество A все элементы из множества B.
|
A & B A.intersection(B) |
Возвращает множество, являющееся пересечением множеств A и B.
|
A &= B A.intersection_update(B) |
Оставляет в множестве A только те элементы, которые есть в множестве B.
|
A - B A.difference(B) |
Возвращает разность множеств A и B (элементы, входящие в A,
но не входящие в B).
|
A -= B A.difference_update(B) |
Удаляет из множества A все элементы, входящие в B.
|
A ^ B A.symmetric_difference(B) |
Возвращает симметрическую разность множеств A и B (элементы, входящие в A
или в B, но не в оба из них одновременно).
|
A ^= B A.symmetric_difference_update(B) |
Записывает в A симметрическую разность множеств A и B.
|
A <= B A.issubset(B) |
Возвращает true |
A >= B A.issuperset(B) |
Возвращает true |
A < B |
Эквивалентно A <= B and A != B
|
A > B |
Эквивалентно A >= B and A != B
|
Во всех упражнениях этого листка ввод-вывод может быть как стандартным,
так и файловым (input.txt/output.txt).
Если ввод-вывод осуществляется со стандартного ввода, то
иногда бывает удобно работать со стандартным вводом, как с файлом.
Для этого необходимо подключить модуль sys, и использовать
объект stdin, определенный в этом модуле, который
связан со стандартным вводом. Например, так:
import sys
for line in sys.stdin.readlines():
...
Для того, чтобы завершить ввод (послать программе сигнал о конце
файла при чтении из стандартного ввода) нужно нажать Ctrl+D
в системе Linux или Ctrl+Z Enter в системе Windows.
Аналогично, для вывода данных на стандартный вывод (на экран)
можно использовать объект stdout и методы файлового вывода
(write).
Дан список чисел, который могут содержать до 100000 чисел каждый. Определите, сколько в нем встречается различных чисел.
| Ввод | Вывод |
|---|---|
1 2 3 2 1 |
3 |
Примечание. Эту задачу на Питоне можно решить в одну строчку.
Даны два списка чисел, которые могут содержать до 100000 чисел каждый. Посчитайте, сколько чисел содержится одновременно как в первом списке, так и во втором.
| Ввод | Вывод |
|---|---|
1 2 3 |
2 |
Примечание. Эту задачу на Питоне можно решить в одну строчку.
Даны два списка чисел, которые могут содержать до 10000 чисел каждый. Выведите все числа, которые входят как в первый, так и во второй список в порядке возрастания.
| Ввод | Вывод |
|---|---|
1 2 3 |
2 3 |
Примечание. И даже эту задачу на Питоне можно решить в одну строчку.
Во входной строке записана последовательность чисел через пробел.
Для каждого числа выведите слово YES (в отдельной строке),
если это число ранее встречалось в последовательности или NO,
если не встречалось.
| Ввод | Вывод |
|---|---|
1 2 3 2 3 4 |
NO |
Аня и Боря любят играть в разноцветные кубики, причем у каждого из них свой набор и в каждом наборе все кубики различны по цвету. Однажды дети заинтересовались, сколько существуют цветов таких, что кубики каждого цвета присутствуют в обоих наборах. Для этого они занумеровали все цвета случайными числами. На этом их энтузиазм иссяк, поэтому вам предлагается помочь им в оставшейся части.
Номер любого цвета — это целое число в пределах от 0 до 109. В первой строке входного файла записаны числа N и M — количество кубиков у Ани и Бори соответственно. В следующих N строках заданы номера цветов кубиков Ани. В последних M строках номера цветов кубиков Бори.
Выведите сначала количество, а затем отсортированные по возрастанию номера цветов таких, что кубики каждого цвета есть в обоих наборах, затем количество и отсортированные по возрастанию номера остальных цветов у Ани, потом количество и отсортированные по возрастанию номера остальных цветов у Бори.
| Ввод | Вывод |
|---|---|
4 3 |
2 |
Во входном файле (вы можете читать данные из файла input.txt)
записан текст. Словом считается последовательность непробельных символов
идущих подряд, слова разделены одним или большим числом пробелов
или символами конца строки.
Определите, сколько различных слов содержится в этом тексте.
| Ввод | Вывод |
|---|---|
She sells sea shells on the sea shore; |
19 |
Август и Беатриса играют в игру. Август загадал натуральное число от 1 до n. Беатриса пытается
угадать это число, для этого она называет некоторые множества натуральных чисел. Август отвечает
Беатрисе YES, если среди названных ей чисел есть задуманное или NO
в противном случае. После нескольких заданныъх вопросов Беатриса запуталась в том, какие вопросы
она задавала и какие ответы получила и просит вас помочь ей определить, какие числа мог задумать Август.
Первая строка входных данных содержит число n — наибольшее число, которое мог загадать
Август. Далее идут строки, содержащие вопросы Беатрисы. Каждая строка представляет собой набор чисел, разделенных
пробелами. После каждой строки с вопросом идет ответ Августа: YES или NO.
Наконец, последняя строка входных данных содержит одно слово HELP. Вы должны вывести (через пробел,
в порядке возрастания) все числа, которые мог задумать Август.
| Ввод | Вывод |
|---|---|
10 |
1 3 5 |
Август и Беатриса продолжают играть в игру, но Август начал жульничать.
На каждый из вопросов Беатрисы он выбирает такой вариант ответа YES или NO,
чтобы множество возможных задуманных чисел оставалось как можно больше. Например,
если Август задумал число от 1 до 5, а Беатриса спросила про числа 1 и 2, то Август
ответит NO, а если Беатриса спросит про 1, 2, 3, то Август ответит YES.
Если же Бетриса в своем вопросе перечисляет ровно половину из задуманных чисел, то Август
из вредности всегда отвечает NO.
Наконец, Август при ответе учитывает все предыдущие вопросы Беатрисы и свои ответы на них, то есть множество возможных задуманных чисел уменьшается.
Вам дана последовательность вопросов Беатрисы. Приведите ответы Августа на них.
Первая строка входных данных содержит число n — наибольшее число, которое мог загадать
Август. Далее идут строки, содержащие вопросы Беатрисы. Каждая строка представляет собой набор чисел, разделенных
пробелами. Последняя строка входных данных содержит одно слово HELP.
Для каждого вопроса Беатрисы выведите ответ Августа на этот вопрос. После этого выведите (через пробел, в порядке возрастания) все числа, которые мог загадать Август после ответа на все вопросы Беатрисы.
| Ввод | Вывод |
|---|---|
10 |
NO |
Каждый из \(N\) школьников некоторой школы знает \(M_i\) языков. Определите, какие языки знают все школьники и языки, которые знает хотя бы один из школьников.
Первая строка входных данных содержит количество школьников \(N\). Далее идет \(N\) чисел \(M_i\), после каждого из чисел идет \(M_i\) строк, содержищих названия языков, которые знает \(i\)-й школьник. Длина названий языков не превышает 1000 символов, количество различных языков не более 1000. \(1 \le N \le 1000\), \(1 \le M_i \le 500\).
| Ввод | Вывод |
|---|---|
3 |
1 |
Политическая жизнь одной страны очень оживленная. В стране действует K политических партий, каждая из которых регулярно объявляет национальную забастовку. Дни, когда хотя бы одна из партий объявляет забастовку, при условии, что это не суббота или воскресенье (когда и так никто не работает), наносят большой ущерб экономике страны.
\(i\)-я партия объявляет забастовки строго каждые \(b_i\) дней, начиная с дня с номером \(a_i\). То есть \(i\)-я партия объявляет забастовки в дни \(a_i\), \(a_i+b_i\), \(a_i+2b_i\) и т.д. Если в какой-то день несколько партий объявляет забастовку, то это считается одной общенациональной забастовкой.
В календаре страны \(N\) дней, пронумерованных от \(1\) до \(N\). Первый день года является понедельником, шестой и седьмой дни недели — выходные, неделя состоит из семи дней.
Программа получает на вход число дней в году \(N\) \((1\le N\le10^6)\) и число политических партий \(K\) \((1\le K\le100)\). Далее идет \(K\) строк, описывающие графики проведения забастовок. \(i\)-я строка содержит числа \(a_i\) и \(b_i\) \((1\le a_i, b_i\le N)\).
Выведите единственное число: количество забастовок, произошедших в течение года.
| Ввод | Вывод |
|---|---|
19 3 |
8 |
Примечание. Первая партия объявляет забастовки в дни 2, 5, 8, 11, 14, 17. Вторая партия объявляет забастовки в дни 3, 8, 13, 18. Третья партия — в дни 9 и 17. Дни номер 6, 7, 13, 14 являются выходными. Таким образом, общенациональные забастовки пройдут в дни 2, 3, 5, 8, 9, 11, 17, 18.
Обычные списки (массивы) представляют собой набор пронумерованных элементов, то есть для обращения к какому-либо элементу списка необходимо указать его номер. Номер элемента в списке однозначно идентифицирует сам элемент. Но идентифицировать данные по числовым номерам не всегда оказывается удобно. Например, маршруты поездов в России идентифицируются численно-буквенным кодом (число и одна цифра), также численно-буквенным кодом идентифицируются авиарейсы, то есть для хранения информации о рейсах поездов или самолетов в качестве идентификатора удобно было бы использовать не число, а текстовую строку.
Структура данных, позволяющая идентифицировать ее элементы не по числовому индексу,
а по произвольному, называется словарем или ассоциативным массивом.
Соответствующая структура данных в языке Питон называется dict.
Рассмотрим простой пример использования словаря. Заведем словарь Capitals,
где индексом является название страны, а значением — название столицы этой страны.
Это позволит легко определять по строке с названием страны ее столицу.
# Создадим пустой словать Capitals
Capitals = dict()
# Заполним его несколькими значениями
Capitals['Russia'] = 'Moscow'
Capitals['Armenia'] = 'Yerevan'
Capitals['Turkey'] = 'Ankara'
# Считаем название страны
print('В какой стране вы живете?')
country = input()
# Проверим, есть ли такая страна в словаре Capitals
if country in Capitals:
# Если есть - выведем ее столицу
print('Столица вашей страны', Capitals[country])
else:
# Запросим название столицы и добавив его в словарь
print('Как называется столица вашей страны?')
city = input()
Capitals[country] = city
Итак, каждый элемент словаря состоит из двух объектов: ключа и значения. В нашем примере ключом является название страны, значением является название столицы. Ключ идентифицирует элемент словаря, значение является данными, которые соответствуют данному ключу. Значения ключей — уникальны, двух одинаковых ключей в словаре быть не может.
В жизни широко распространены словари, например, привычные бумажные словари (толковые, орфографические, лингвистические). В них ключом является слово-заголовок статьи, а значением — сама статья. Для того, чтобы получить доступ к статье, необходимо указать слово-ключ.
Другой пример словаря, как структуры данных — телефонный справочник. В нем ключом является имя, а значением — номер телефона. И словарь, и телефонный справочник хранятся так, что легко найти элемент словаря по известному ключу (например, если записи хранятся в алфавитном порядке ключей, то легко можно найти известный ключ, например, бинарным поиском), но если ключ неизвествен, а известно лишь значение, то поиск элемента с данным значением может потребовать последовательного просмотра всех элементов словаря.
Особенностью ассоциативного массива является его динамичность: в него можно добавлять новые элементы с произвольными ключами и удалять уже существующие элементы. При этом размер используемой памяти пропорционален размеру ассоциативного массива. Доступ к элементам ассоциативного массива выполняется хоть и медленнее, чем к обычным массивам, но в целом довольно быстро.
В языке Питон как ключом может быть произвольный неизменяемый тип данных:
целые и действительные числа, строки, кортежи. Ключом в словаре не может
быть множество, но может быть элемент типа frozenset: специальный
тип данных, являющийся аналогом типа set, который нельзя изменять после создания.
Значением элемента словаря может быть любой тип данных, в том числе и изменяемый.
Словари нужно использовать в следующих случаях:
Num['January'] = 1; Num['February'] = 2; ....
Пустой словарь можно создать при помощи функции dict() или
пустой пары фигурных скобок {} (вот почему фигурные скобки
нельзя использовать для создания пустого множества). Для создания словаря
с некоторым набором начальных значений можно использовать следующие конструкции:
Capitals = {'Russia': 'Moscow', 'Armenia': 'Yerevan', 'Turkey': 'Ankara'}
Capitals = dict(Russia = 'Moscow', Armenia = 'Yerevan', Turkey = 'Ankara')
Capitals = dict([("Russia", "Moscow"), ("Armenia", "Yerevan"), ("Turkey", "Ankara")])
Capitals = dict(zip(["Russia", "Armenia", "Turkey"], ["Moscow", "Yerevan", "Ankara"]))
Первые два способа можно использовать только для создания небольших словарей, перечисляя все их элементы.
Кроме того, во втором способе ключи передаются как именованные параметры функции dict, поэтому
в этом случае ключи могут быть только строками, причем являющимися корректными идентификаторами.
В третьем и четвертом случае можно создавать большие словари, если в качестве аргументов
передавать уже готовые списки, которые могут быть получены не обязательно перечислением всех элементов,
а любым другим способом построены по ходу исполнения программы. В третьем способе
функции dict нужно передать список, каждый элемент которого является кортежем
из двух элементов: ключа и значения. В четвертом способе используется функция zip,
которой передается два списка одинаковой длины: список ключей и список значений.
Основная операция: получение значения элемента по ключу, записывается так же, как и для
списков: A[key]. Если элемента с заданным ключом не существует в словаре,
то возникает исключение KeyError.
Другой способ определения значения по ключу — метод get:
A.get(key). Если элемента с ключом get нет в словаре,
то возвращается значение None. В форме записи с двумя аргументами
A.get(key, val) метод возвращает значение val,
если элемент с ключом key отсутствует в словаре.
Проверить принадлежность элемента словарю можно операциями in
и not in, как и для множеств.
Для добавления нового элемента в словарь нужно просто присвоить ему какое-то значение:
A[key] = value.
Для удаления элемента из словаря можно использовать операцию del A[key]
(операция возбуждает исключение KeyError, если такого ключа в словаре нет.
Вот два безопасных способа удаления элемента из словаря. Способ с предварительной
проверкой наличия элемента:
if key in A:
del A[key]
Способ с перехватыванием и обработкой исключения:
try:
del A[key]
except KeyError:
pass
Еще один способ удалить элемент из словаря: использование метода pop:
A.pop(key). Этот метод возвращает значение удаляемого элемента, если
элемент с данным ключом отсутствует в словаре, то возбуждается исключение. Если
методу pop передать второй параметр, то если элемент в словаре отсутствует,
то метод pop возвратит значение этого параметра. Это позволяет
проще всего организовать безопасное удаление элемента из словаря: A.pop(key, None).
Можно легко организовать перебор ключей всех элементов в словаре:
for key in A:
print(key, A[key])
Следующие методы возвращают представления элементов словаря.
Представления во многом похожи на множества, но они изменяются,
если менять значения элементов словаря. Метод keys
возвращает представление ключей всех элементов, метод values
возвращает представление всех значений, а метод items
возвращает представление всех пар (кортежей) из ключей и значений.
Соответственно, быстро проверить, если ли значение val
среди всех значений элементов словаря A можно так:
val in A.values(), а организовать цикл так, чтобы
в переменной key был ключ элемента, а в переменной val
было его значение можно так:
for key, val in A.items():
print(key, val)
Во входном файле (вы можете читать данные из файла input.txt)
записан текст. Словом считается последовательность непробельных символов
идущих подряд, слова разделены одним или большим числом пробелов
или символами конца строки.
Для каждого слова из этого текста подсчитайте, сколько раз оно встречалось в этом тексте ранее.
| Ввод | Вывод |
|---|---|
one two one two three |
0 0 1 1 0 |
She sells sea shells on the sea shore; |
0 0 0 0 0 0 1 0 0 1 0 0 1 0 2 2 0 0 0 0 1 2 3 3 1 1 4 0 1 0 1 2 4 1 5 0 0 |
Вам дан словарь, состоящий из пар слов. Каждое слово является синонимом к парному ему слову. Все слова в словаре различны. Для одного данного слова определите его синоним.
Программа получает на вход словарь синонимов. Каждая строка словаря содержит два слова, разделенных пробелами. Далее до конца файла идет последовательность слов (по одному слову в строке).
Программа должна для каждого слова вывести его синоним.
| Ввод | Вывод |
|---|---|
Hello Hi |
Bye |
Эту задачу можно решить и без словарей (сохранив все входные данные в списке), но решение со словарем будет более простым.
Как известно, в США президент выбирается не прямым голосованием, а путем двухуровневого голосования. Сначала проводятся выборы в каждом штате и определяется победитель выборов в данном штате. Затем проводятся государственные выборы: на этих выборах каждый штат имеет определенное число голосов — число выборщиков от этого штата. На практике, все выборщики от штата голосуют в соответствии с результами голосования внутри штата, то есть на заключительной стадии выборов в голосовании участвуют штаты, имеющие различное число голосов.
Вам известно за кого проголосовал каждый штат и сколько голосов было отдано данным штатом. Подведите итоги выборов: для каждого из участника голосования определите число отданных за него голосов.
Каждая строка входного файла содержит фамилию кандидата, за которого отдают голоса выборщики этого штата, затем через пробел идет количество выборщиков, отдавших голоса за этого кандидата.
Выведите фамилии всех кандидатов в лексикографическом порядке, затем, через пробел, количество отданных за них голосов.
| Ввод | Вывод |
|---|---|
McCain 10 |
McCain 16 |
Ivanov 1 |
Ivanov 1 |
Дан текст. Выведите слово, которое в этом тексте встречается чаще всего. Если таких слов несколько, выведите то, которое меньше в лексикографическом порядке.
| Ввод | Вывод |
|---|---|
apple orange banana banana orange |
banana |
В файловую систему одного суперкомпьютера проник вирус, который сломал контроль за правами доступа к файлам. Для каждого файла \(N_i\) известно, с какими действиями можно к нему обращаться:
W,
R,
X.
Вам требуется восстановить контроль над правами доступа к файлам
(ваша программа для каждого запроса должна будет возвращать OK
если над файлом выполняется допустимая операция, или же
Access denied, если операция недопустима.
В первой строке входного файла содержится число \(N\) (\(1 \le N \le 10000\)) —количество файлов содержащихся в данной файловой системе.
В следующих \(N\) строчках содержатся имена файлов и допустимых с ними операций, разделенные пробелами. Длина имени файла не превышает 15 символов.
Далее указано чиcло \(M\) (\(1 \le M \le 50000\)) — количество запросов к файлам.
В последних \(M\) строках указан запрос вида Операция Файл.
К одному и тому же файлу может быть применено любое колличество запросов.
Для каждого из \(M\) запросов нужно вывести в отдельной строке
Access denied или OK.
| Ввод | Вывод |
|---|---|
4 |
OK |
Дан текст. Выведите все слова, встречающиеся в тексте, по одному на каждую строку. Слова должны быть отсортированы по убыванию их количества появления в тексте, а при одинаковой частоте появления — в лексикографическом порядке.
| Ввод | Вывод |
|---|---|
hi |
damme |
Указание. После того, как вы создадите словарь всех слов, вам захочется отсортировать
его по частоте встречаемости слова. Желаемого можно добиться, если создать список,
элементами которого будут кортежи из двух элементов: частота встречаемости слова
и само слово. Например, [(2, 'hi'), (1, 'what'), (3, 'is')].
Тогда стандартная сортировка будет сортировать список кортежей, при этом
кортежи сравниваются по первому элементу, а если они равны —
то по второму. Это почти то, что требуется в задаче.
Дан список стран и городов каждой страны. Затем даны названия городов. Для каждого города укажите, в какой стране он находится.
Программа получает на вход количество стран \(N\). Далее идет \(N\) строк, каждая строка начинается с названия страны, затем идут названия городов этой страны. В следующей строке записано число \(M\), далее идут \(M\) запросов — названия каких-то \(M\) городов, перечисленных выше.
Для каждого из запроса выведите название страны, в котором находится данный город.
| Ввод | Вывод |
|---|---|
2 |
Inca |
Некоторый банк хочет внедрить систему управления счетами клиентов, поддерживающую следующие операции:
Вам необходимо реализовать такую систему. Клиенты банка идентифицируются именами (уникальная строка, не содержащая пробелов). Первоначально у банка нет ни одного клиента. Как только для клиента проводится операция пололнения, снятия или перевода денег, ему заводится счет с нулевым балансом. Все дальнейшие операции проводятся только с этим счетом. Сумма на счету может быть как положительной, так и отрицательной, при этом всегда является целым числом.
Входной файл содержит последовательность операций. Возможны следующие операции:
DEPOSIT name sum - зачислить сумму sum на счет клиента name.
Если у клиента нет счета, то счет создается.
WITHDRAW name sum - снять сумму sum со счета клиента name.
Если у клиента нет счета, то счет создается.
BALANCE name - узнать остаток средств на счету клиента name.
TRANSFER name1 name2 sum - перевести сумму sum со счета клиента name1
на счет клиента name2. Если у какого-либо клиента нет счета, то ему создается счет.
INCOME p - начислить всем клиентам, у которых открыты счета, p%
от суммы счета. Проценты начисляются только клиентам с положительным остатком на счету,
если у клиента остаток отрицательный, то его счет не меняется. После начисления процентов
сумма на счету остается целой, то есть начисляется только целое число денежных единиц.
Дробная часть начисленных процентов отбрасывается.
Для каждого запроса BALANCE программа должна вывести остаток на счету данного
клиента. Если же у клиента с запрашиваемым именем не открыт счет в банке, выведите
ERROR.
| Ввод | Вывод |
|---|---|
DEPOSIT Ivanov 100 |
105 |
Однажды, разбирая старые книги на чердаке, школьник Вася нашёл англо-латинский словарь. Английский он к тому времени знал в совершенстве, и его мечтой было изучить латынь. Поэтому попавшийся словарь был как раз кстати.
К сожалению, для полноценного изучения языка недостаточно только одного словаря: кроме англо-латинского необходим латинско-английский. За неимением лучшего он решил сделать второй словарь из первого.
Как известно, словарь состоит из переводимых слов, к каждому из которых приводится несколько слов-переводов. Для каждого латинского слова, встречающегося где-либо в словаре, Вася предлагает найти все его переводы (то есть все английские слова, для которых наше латинское встречалось в его списке переводов), и считать их и только их переводами этого латинского слова.
Помогите Васе выполнить работу по созданию латинско-английского словаря из англо-латинского.
В первой строке содержится единственное целое число N — количество английских слов в словаре. Далее следует N описаний. Каждое описание содержится в отдельной строке, в которой записано сначала английское слово, затем отделённый пробелами дефис (символ номер 45), затем разделённые запятыми с пробелами переводы этого английского слова на латинский. Переводы отсортированы в лексикографическом порядке. Порядок следования английских слов в словаре также лексикографический.
Все слова состоят только из маленьких латинских букв, длина каждого слова не превосходит 15 символов. Общее количество слов на входе не превышает 100000.
Выведите соответствующий данному латинско-английский словарь, в точности соблюдая формат входных данных. В частности, первым должен идти перевод лексикографически минимального латинского слова, далее — второго в этом порядке и т.д. Внутри перевода английские слова должны быть также отсортированы лексикографически.
| Ввод | Вывод |
|---|---|
3 |
7 |
Учительница задала Пете домашнее задание — в заданном тексте расставить ударения в словах, после чего поручила Васе проверить это домашнее задание. Вася очень плохо знаком с данной темой, поэтому он нашел словарь, в котором указано, как ставятся ударения в словах. К сожалению, в этом словаре присутствуют не все слова. Вася решил, что в словах, которых нет в словаре, он будет считать, что Петя поставил ударения правильно, если в этом слове Петей поставлено ровно одно ударение.
Оказалось, что в некоторых словах ударение может быть поставлено больше, чем одним способом. Вася решил, что в этом случае если то, как Петя поставил ударение, соответствует одному из приведенных в словаре вариантов, он будет засчитывать это как правильную расстановку ударения, а если не соответствует, то как ошибку.
Вам дан словарь, которым пользовался Вася и домашнее задание, сданное Петей. Ваша задача — определить количество ошибок, которое в этом задании насчитает Вася.
Вводится сначала число N — количество слов в словаре (0≤N≤20000).
Далее идет N строк со словами из словаря. Каждое слово состоит не более чем из 30 символов. Все слова состоят из маленьких и заглавных латинских букв. В каждом слове заглавная ровно одна буква — та, на которую попадает ударение. Слова в словаре расположены в алфавитном порядке. Если есть несколько возможностей расстановки ударения в одном и том же слове, то эти варианты в словаре идут в произвольном порядке.
Далее идет упражнение, выполненное Петей. Упражнение представляет собой строку текста, суммарным объемом не более 300000 символов. Строка состоит из слов, которые разделяются между собой ровно одним пробелом. Длина каждого слова не превышает 30 символов. Все слова состоят из маленьких и заглавных латинских букв (заглавными обозначены те буквы, над которыми Петя поставил ударение). Петя мог по ошибке в каком-то слове поставить более одного ударения или не поставить ударения вовсе.
Выведите количество ошибок в Петином тексте, которые найдет Вася.
| Ввод | Вывод | Комментарии |
|---|---|---|
4 |
2 |
В слове cannot, согласно словарю возможно два варианта расстановки ударения. Эти варианты в словаре могут быть перечислены в любом порядке (т.е. как сначала cAnnot, а потом cannOt, так и наоборот). Две ошибки, совершенные Петей — это слова be (ударение вообще не поставлено) и fouNd (ударение поставлено неверно). Слово thE отсутствует в словаре, но поскольку в нем Петя поставил ровно одно ударение, признается верным. |
4 |
4 |
Неверно расставлены ударения во всех словах, кроме The (оно отсутствует в словаре, в нем поставлено ровно одно ударение). В остальных словах либо ударные все буквы (в слове PAGE), либо не поставлено ни одного ударения. |
Дана база данных о продажах некоторого интернет-магазина.
Каждая строка входного файла представляет собой запись вида
Покупатель товар количество, где
Покупатель — имя покупателя (строка без пробелов),
товар — название товара (строка без пробелов),
количество — количество приобретенных единиц
товара.
Создайте список всех покупателей, а для каждого покупателя подсчитайте количество приобретенных им единиц каждого вида товаров.
Выведите список всех покупателей в лексикографическом порядке, после имени каждого покупателя выведите двоеточие, затем выведите список названий всех приобретенных данным покупателем товаров в лексикографическом порядке, после названия каждого товара выведите количество единиц товара, приобретенных данным покупателем. Информация о каждом товаре выводится в отдельной строке.
| Ввод | Вывод |
|---|---|
Ivanov paper 10 |
Ivanov: |
Указание. В этой задаче удобно завести словарь, в котором ключом является имя человека, а значением — набор его покупок. Набор его покупок в свою очередь представляет собой таже словарь, где ключом является название товара, а значением — его количество. Таким образом, получится словарь, каждый элемент которого также является словарем.
На этот раз вам известно число выборщиков от каждого штата США и результаты голосования каждого гражданина США (а также в каком штате проживает данный гражданин).
Вам необходимо подвести результаты голосования: сначала определить результаты голосования в каждом штате и определить, за какого из кандидатов отданы голоса выборщиков данного штата. Далее необходимо подвести результаты голосования выборщиков по всем штатам.
Первая строка входных данных содержит количество штатов в США N. Далее идет N строк, описывающих штаты США, каждая строка состоит из названия штата и числа выборщиков от этого штата. Далее до конца файла идут записи результатов голосования по каждому из участников голосования. Одна строка соответствует одному избирателю. Записи имеют вид: название штата, имя кандидата, за которого проголосовал данный избиратель. Названия штатов и имена кандидатов не содержат пробелов.
Выведите список кандидатов, упорядоченный по убыванию числа голосов выборщиков, полученных за данного кандидата, а при равенстве числа голосов выборщиков: в лексикографическом порядке. После имени кандидата выведите число набранных им голосов.
Если в каком-либо штате два или более число кандидатов набрали одинаковое число голосов, то все голоса выборщиков этого штата получает наименьший в лексикографическом порядке кандидат из числа победителей в этом штате.
Гарантируется, что в каждом штате проголосовал хотя бы один избиратель.
| Ввод | Вывод | Комментарии |
|---|---|---|
2 |
Bush 25 |
В Florida 2 избирателя голосует за Gore и три избирателя
за Bush, поэтому 25 голосов выборщиков от Floria получает Bush. В Pennsylvania
побеждает Gore (4 голоса против 1), поэтому Gore получает 23 голоса выборщиков от Pennsylvania. |
3 |
Gore 5 |
В Florida побеждает Gore (5 голосов выборщиков), в Alaska — Bush (2 голоса выборщика). В Pennsylvania два кандидата набрали наибольшее число голосов (по 1), поэтому
4 голоса выборщиков от этого штата получает Clinton, т.к. он идет раньше в лексикографическом порядке. |
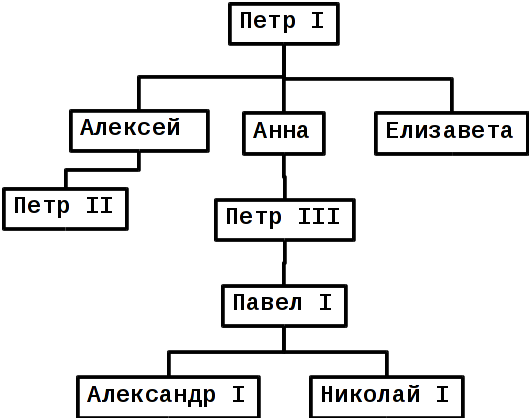
В генеалогическом древе у каждого человека, кроме родоначальника, есть ровно один родитель. На рисунке приведена часть древа рода Романовых, начиная с Петра I Великого.
Каждом элементу дерева сопоставляется целое неотрицательное число, называемое высотой. У родоначальника высота равна 0, у любого другого элемента высота на 1 больше, чем у его родителя.
Вам дано генеалогическое древо, определите высоту всех его элементов.
Программа получает на вход число элементов в генеалогическом древе \(N\). Далее
следует \(N-1\) строка, задающие родителя для каждого элемента древа, кроме родоначальника.
Каждая строка имеет вид имя_потомка имя_родителя.
Программа должна вывести список всех элементов древа в лексикографическом порядке. После вывода имени каждого элемента необходимо вывести его высоту.
Эта задача имеет решение сложности \(O(n)\), но вам достаточно написать решение сложности \(O(n^2)\) (не считая сложности обращения к элементам словаря).
Пример ниже соответствует приведенному древу рода Романовых.
| Ввод | Вывод |
|---|---|
9 |
Alexander_I 4 |
Даны два элемента в дереве. Определите, является ли один из них потомком другого.
Программа получает на вход описание дерева, как в задаче W. Далее до конца файла идут строки, содержащие имена двух элементов дерева. Для каждого такого запроса выведите одно из трех чисел: 1, если первый элемент является предком второго, 2, если второй является предком первого или 0, если ни один из них не является предком другого.
| Ввод | Вывод |
|---|---|
9 |
1 |
В генеалогическом древе определите для двух элементов их наименьшего общего предка. Наименьшим общим предком элементов A и B является такой элемент C, что С является предком A, C является предком B, при этом глубина C является наибольшей из возможных. При этом элемент считается своим собственным предком.
Формат входных данных аналогичен предыдущей задаче. Для каждого запроса выведите наименьшего общего предка данных элементов.
По-английски такая задача называется lowest common ancestor (LCA).
| Ввод | Вывод |
|---|---|
9 |
Paul_I |
Для каждого элемента дерева определите число всех его потомков (не считая его самого).
Формат выходных данных совпадает с задачей W. Выведите список всех элементов в лексикографическом порядке, для каждого элемента выводите количество всех его потомков.
Решение должно иметь сложность \(O(N)\), не считая сложности обращения к элементам словаря и сортировки результата.
| Ввод | Вывод |
|---|---|
9 |
Alexander_I 0 |